Parallel builds
Running a build's steps in parallel is a way to decrease your build's total running time. This guide will show you how to use multiple agents and job parallelism to increase the speed of your builds.
Command steps run in parallel by default. If you define multiple steps, and run multiple agents, the steps will run at the same time across your agents.
If you don't want your steps to run at the same time, you can add wait steps or use dependencies. For example, you could have a test step and a deploy step, with a wait step in between.
A single command step can also be broken up into many parallel jobs. For example, a long-running test suite can be split into many parallel pieces across multiple agents, reducing the total run time of your build.
Running multiple agents
There are two ways to scale your build agents: horizontally across multiple machines, or vertically on a single machine. You can even run many agents per machine across many machines.
Multiple agents on one machine
The steps for running multiple agents are slightly different for each platform. Automated installers and detailed instructions can be found in the installation section. But the simplest example is to use the spawn option when starting the agent:
# After running the standard install instructions...
# Start five agents
buildkite-agent start --spawn 5
This will start a single process, but can run up to 5 different jobs at the same time.
The start command can also be run multiple times with different configurations. For example, to change the queue:
buildkite-agent start --tags queue=test
# In another window, or tab
buildkite-agent start --tags queue=deploy
Coordinating multiple agents
To use it, set experiment="agent-api" in your agent configuration.
This requires Agent v3.47.0 or later.
Multiple agents on a single host can sometimes interfere with one another. For example, a pipeline might contain commands like docker prune or apt upgrade, but these commands fail if another job runs the same command at the same time.
To coordinate access to shared resources on the same host, you can use agent locks. Locking is advisory (nothing prevents a buggy command from ignoring a lock), but it can help avoid multiple agents interfering with each other.
Here's how you could use locks in a script to make sure a command is run by only one agent at a time:
# Acquire the lock called "docker prune", and store the token.
token=$(buildkite-agent lock acquire "docker prune")
# Once the lock is acquired, proceed to run the command - in this example, docker prune
docker prune
# Release the lock afterwards.
# To make this example more robust, consider using an EXIT trap, so that the lock is released whether the command succeeded or not.
buildkite-agent lock release "docker prune" "${token}"
Multiple agents on many machines
The secret to fast builds is running as many build agents as you can. The best way to do that is to have many machines running build agents. These machines can be anything ranging from your laptop, a few spare computers in your office, to a fleet of thousands of cloud compute instances.
The Buildkite agent should run on any hardware and any cloud compute provider. It is built to be flexible, and can be composed in any way that suits the platform, infrastructure, or workload. The installation instructions demonstrate how to run the Buildkite agent across various platforms.
For example, you could start several Google Cloud Compute instances, then install and start build agents. These instructions can be automated using infrastructure as code tools like Terraform, and then add auto-scaling rules so you always have enough capacity.
The Elastic CI Stack for AWS provides a pre-built CloudFormation Stack for AWS that runs multiple auto-scaling agents.
Parallel jobs
parallelism is an attribute on a single command step which causes it to be split into many jobs. Those jobs will be the same except for having a parallel index and count. They share the same dependencies and agent tags.
To run the same step in parallel over all 5 of the agents, we can set the parallelism field for a single build step:
steps:
- command: "tests.sh"
parallelism: 5
Update the name of the step to include %n, like the example below. This will include a number at runtime so that you can differentiate between the parallel build jobs.
steps:
- command: "tests.sh"
label: "Test %n"
parallelism: 5
You can choose from the following parallel job index label helpers:
-
%nto display job count starting at0. -
%Nto display job count starting at1. -
%tto display the total number of parallel jobs as of when the job was created. -
%Tto display the step's current parallelism, which reflects any updates made usingbuildkite-agent step update parallelism <value>.
Use %T instead of %t when you use buildkite-agent step update parallelism <value> to expand a parallel group at runtime. In that case, %t reflects the original job count at creation time. %T reflects the updated total for all jobs in the step.
For example, if a parallel group starts with two jobs and is then expanded to five:
- A label containing
%N/%trenders1/2and2/2for the original jobs, then3/5,4/5, and5/5for the new jobs. - A label containing
%N/%Trenders1/5,2/5,3/5,4/5, and5/5for all jobs.
Now that the pipeline is configured, create a new build:
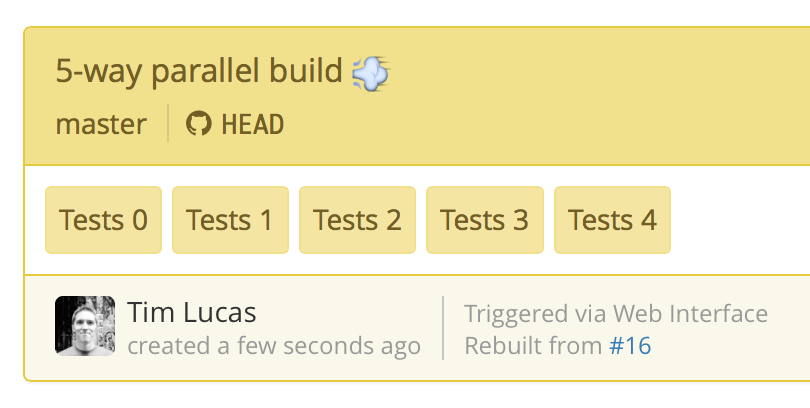
If you inspect the first job's environment variables you'll find:
BUILDKITE_PARALLEL_JOB=0
BUILDKITE_PARALLEL_JOB_COUNT=5
The BUILDKITE_PARALLEL_JOB environment variable stores the index of each parallel job created from a parallel build step, starting from 0. For a build step with parallelism: 5, the value would be 0, 1, 2, 3, and 4 respectively.
The BUILDKITE_PARALLEL_JOB_COUNT environment variable stores the total number of jobs created from this step for this build.
You can use these two environment variables to divide your application's tests between the different jobs.
Libraries
For best results, Buildkite recommends using the Test Engine Client (bktec) tool, which supports parallel jobs. bktec uses your Test Engine test suite data to provide intelligent test splitting and automatic management of flaky tests. For more information, see Speed up builds with the Test Engine Client and its configuration options.
Other libraries that have built-in support for the BUILDKITE_PARALLEL_JOB and BUILDKITE_PARALLEL_JOB_COUNT environment variables are:
Knapsack
Knapsack is a ruby gem for automatically dividing your tests between parallel jobs, as well as making sure each job runs in comparable time. It supports RSpec, Cucumber, and minitest.Knapsack Pro
A commercially supported version of Knapsack that provides a hosted service for test timing data and additional job distribution modes for Ruby, JavaScript, and more. See the README and step-by-step tutorial for Ruby setup instructions and example pipelines. For other programming languages please check integrations.Shardy McShardFace
Shardy McShardFace is an npm package for dividing your tests between parallel jobs. it shards as evenly as possible, uneven splits will end up in the tail shards, supports sharding fewer items than the parallelism count, and distributes items into shards based on a given seed for a random number generator to provide random, but stable distribution. See their README for more information.
Isolated jobs
You can safely run multiple build jobs on a single machine, as the agent runs each build in its own checkout directory. You'll still need to ensure your application supports running in parallel on the same machine, and doesn't try to write to any shared resources at the same time (such as modifying the same database at the same time).
One convenient way of achieving build job isolation is to use the agent's built in Docker Compose support which will run each job inside a set of completely isolated Docker containers.
Auto-scaling your build agents
In addition to the Elastic CI Stack for AWS (which has built-in support for auto-scaling) we provide a number of APIs and tools you can use to auto-scale your own build agents:
- GraphQL API allows you to efficiently fetch your organization's scheduled jobs count, agents count, and details about each agent.
- Pipelines REST API and Agents API you're able to fetch each pipeline's job count, and information about each agent.
- Agent priorities allow you to define which agents are assigned work first, such as high performance ephemeral agents.
- Agent queues allow you to divide your agent pools into separate groups for scaling and performance purposes.
- buildkite-agent-metrics tool allows you to collect your organization's Buildkite metrics and report them to a range of backends including AWS CloudWatch, StatsD, Prometheus, and OpenTelemetry.
Using these tools you can automate your build infrastructure, scale your agents based on demand, and massively reduce build times using job parallelism.
Overloaded single steps
Avoid cramming unrelated tasks into one step, for example:
# ❌ Bad - Mixing unrelated concerns
- label: "Build and security scan and deploy"
command: |
docker build -t myapp .
trivy image myapp
docker push myapp:latest
kubectl apply -f k8s/deployment.yaml
# ✅ Good - Separate logical concerns
- label: "<img class="emoji" title="docker" alt=":docker:" src="https://buildkiteassets.com/emojis/img-buildkite-64/docker.png" draggable="false" /> Build application"
command: "docker build -t myapp ."
- label: "🛡️ Security scan"
command: "trivy image myapp"
depends_on: "build"
- label: "🚀 Deploy to production"
command: |
docker push myapp:latest
kubectl apply -f k8s/deployment.yaml
depends_on:
- "build"
- "security-scan"
The "bad" example crams together building, security scanning, and deployment which are three totally different concerns that you'd want to handle separately, potentially with different permissions, agents, and failure handling strategies.
Cramming more tasks into one step reduces the ability of the pipeline to scale and take advantage of multiple agents. Splitting steps makes it logically easier to understand and also takes advantage of Buildkite's scalable agents. Also makes it easier to troubleshoot when something breaks in the pipeline.
Controlled parallelism and concurrency
Balance parallel execution for speed while managing resource consumption and costs:
Step-level parallelism (parallelism attribute):
- Set reasonable limits on the
parallelismattribute for individual steps based on your agent capacity. - Consider that each parallel job consumes an agent, so
parallelism: 50requires 50 available agents. - Monitor queue wait times when using high parallelism values to ensure adequate agent availability.
Build-level concurrency:
- While running jobs in parallel across different steps speeds up builds, be mindful of your total agent pool capacity.
- Buildkite has default limits on concurrent steps per build to prevent resource exhaustion.
- Design pipeline dependencies (
waitsteps) to balance speed with resource availability.
Example of controlled parallelism:
steps:
- label: "Unit Tests"
command: npm test
parallelism: 10 # Reasonable for most agent pools
- wait
- label: "Integration Tests"
command: npm run test:integration
parallelism: 5 # Lower parallelism for resource-intensive tests