Would you run your entire CI/CD workload on machines that might stop at any time? What if those machines were much cheaper than your usual compute, only ran your fault-tolerant CI jobs, and those jobs automatically resumed without duplicating work? Using AWS Spot Instances and Buildkite Pipelines makes this a reality.
Spot Instances are a great addition to your CI/CD infrastructure, but there are risks to mitigate. In this blog we’ll discuss ways to avoid duplicated work, handle interruptions, and find efficient ways to retry pipelines when using less stable instances.
Are Spot Instances a good fit for CI/CD?
First, what is a Spot Instance? When paying for an On-Demand Amazon EC2 instance, there’s an assurance that the instance will continue to be available for as long as needed. Spot Instances are unused EC2 instances, offered at a discount, that AWS can reclaim at any time.
So why add this type of instance to your fleet? Well, there are a few compelling reasons:
- Cost savings. Have an equivalent EC2 instance for a steep discount (up to 90%).
- Scalability. With the same spend, you can have more Spot Instances than On-Demand Instances. The result is more processing power to run your pipelines, and a better developer experience.
- Parallelization. With multiple runners you can parallelize your pipeline’s tasks for faster runs. For example, using parallel runs for your tests.
The main downside is that they can be interrupted at any time with a two-minute notice. Depending on the region, instance type, and availability zone, Spot Instances may run a surprisingly long time. But in the worst case, they can also terminate during critical work that has to be restarted.
As well as duplicated work, Spot interruptions can mean extended task times, lower pipeline efficiency, and developers waiting around. Nobody likes it when complex test suites take even longer to run, or when the build needs to be retried. Considering the drawbacks is essential before incorporating Spot Instances into your fleet.
Strategies to manage interruptions
Let’s assume your CI/CD jobs will be interrupted. You can mitigate the effects of interruptions and make your jobs more likely to succeed with the following strategies.
Reduce job times
If a job takes half as long to complete, there’s less time for it to be interrupted. There are a lot of ways to reduce job times, such as:
- Parallelize your jobs so each step is shorter.
- Identify slow-running tests to optimize.
- Use caching to speed up build times.
- Create and target queues with the right-sized hardware for the job.
There are many other ways to speed up your jobs, but these are good places to start.
Create checkpoints
With Spot Instance termination, your instance has two minutes to complete its work and shut down. Your tooling may let you preserve its current state by creating a checkpoint, which can be restored when retrying the job. Build artifacts are a great place to store this progress information—however, how you preserve and restore state will depend on the pipeline.
Let’s look at a concrete example with test suites. If you record which tests have succeeded, your test runner can skip those tests on a retry. Rippling has implemented checkpoints with Pytest to do this and open-sourced their test runner modifications.
Here’s how this process looks in practice:
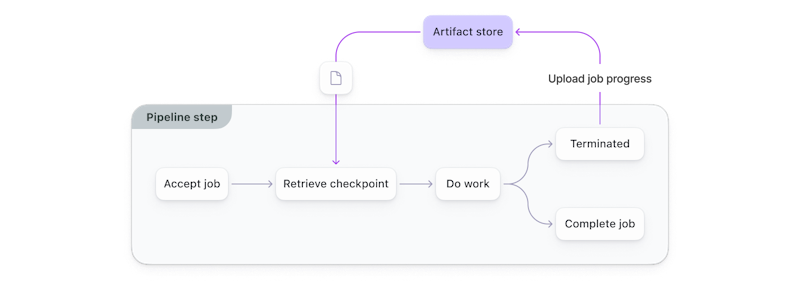
The latest checkpoint is downloaded at the start of new runs, work is started or resumed, and a new checkpoint is uploaded if the task is terminated.
Ensure retries happen
Your Spot Instance interruption behavior and CI/CD configuration controls how and when retries happen. It’s important to get those settings right so your pipelines continue when failures happen.
To ensure retries happen:
- Check your Spot Instances Terminate when interrupted, rather than Stop or Hibernate. The storage/memory of your stopped or hibernated instances is kept in Amazon EBS volumes, which you get charged to store. In comparison, terminated instances are completely deleted with no ongoing costs.
- Set your CI/CD system to retry tasks when the runner is stopped or loses connection to the control plane. Buildkite has retry attributes to configure this behavior, but on other CI/CD tools, search for terms like “timeouts,” “interruptions,” and “persist.”
Implementing retry mechanisms with Buildkite
Buildkite Pipeline's hybrid architecture separates the compute infrastructure from the control plane. Buildkite manages the control plane and you provide the compute, making it easy to use Spot Instances with Buildkite. Here’s a high-level overview:
- Your machines (Spot Instances) run the Buildkite Agent.
- The agent executes available jobs.
- The dashboard keeps track of which agents are executing jobs and listens for shutdowns of the agent or communication being lost. A recent change lowers the agent timeouts, specifically to help with Spot and other easily interrupted machines.
Failed jobs can be retried automatically (triggered by Buildkite) or manually (via the dashboard or with an API call). The retry attributes configured in the pipeline definition control how this works.
Configure at the step level
Each step in your pipeline has different considerations that affect whether the step can be interrupted and safely retried. For example, test steps usually don’t change external data, systems, or infrastructure, but deploy steps do and must be configured differently.
On each pipeline step, you can set the queue to determine whether a step is run on Spot Instances or not, and set the automatic retry attributes based on when a step is suitable to re-run.
Automatic retries are the quickest way to get your pipeline to continue, so we’ll focus on those attributes. Here’s an example that retries jobs when the agent stops or disconnects from Buildkite:
retry:
automatic:
- exit_status: -1 # Connection to the Agent was lost
signal_reason: none
limit: 2
- signal_reason: agent_stop # Agent was stopped by the OS (e.g. spot termination)
limit: 4The first matching entry indicates the retry limit. In this case, two retries if the agent disconnects, and four on agents being terminated.
Here are the automatic retry attributes you can use in each entry:
exit_status: The exit code of the process.-1is a special exit code indicating the dashboard can no longer communicate with the agent. See the documentation for the other special exit codes.signal: The signal that caused this process to exit (for incoming, uncaught signals).signal_reason: The reason a process was signaled. Here are the possible values:none: No signal was sent to the process.cancel: The job was canceled in the Buildkite dashboard.agent_stop: The agent was stopped.
limit: The number of times this job can be retried.
These attributes let you specify which steps to retry and when to retry them, so you can handle Spot interruptions in the way that works best for your pipelines.
Common use cases for retry options
Automatic retry options let you handle cases other than Spot termination as well. For example:
- Retrying flaky tests. If you use checkpoints, you may only need to re-run the specific tests that failed or haven’t run yet. Of course, if you’d like help identifying which tests are flaky or slow, try Buildkite Test Analytics.
- Avoiding futile retries. You may have an error that you know won’t resolve when retried. In this case, add an entry with
limit: 0and Buildkite won’t retry the job.
Here’s an example with some extra features, including disabled retries on a specific failure:
retry:
automatic:
- exit_status: -1 # Connection to the Agent was lost
signal_reason: none
limit: 2
- signal_reason: agent_stop # Agent was stopped by the OS (e.g. spot termination)
limit: 4
- exit_status: 120 # Deploy server rejected the build for signature reasons. Our signature will need to be updated so let's not retry
limit: 0
- limit: 2 # Retry twice to account for flaky testsYou can use this as a base, adding and configuring entries to fit your pipeline’s retry needs.
Conclusion
Spot Instances can be a valuable addition to your compute fleet. However, you need to be careful to mitigate the challenges of machines terminating while running a job. Reducing build times, creating checkpoints, and setting up retry logic are all strategies you can use to overcome those challenges.
A robust retry strategy can also help with the developer experience at your organization. Setting up automatic retries can save a lot of time.
Beyond Spot Instances, these techniques will also improve the overall resilience and reliability of your CI/CD pipelines.
If you'd like to learn more about AWS Spot Instances, register for our webinar: How Rippling reduced cost and improved developer experience by moving CI to Spot Instances.
Buildkite Pipelines is a CI/CD tool designed for developer happiness. Easily follow and decipher logs, get observability into key build metrics, and tune for enterprise-grade speed, scale, and security. Every new signup gets a free 30-day trial to test out the key features. See Buildkite Pipelines to learn more.




