
As software developers, our initial reaction when an incident occurs is often to dig into the details and find the root cause. We try breaking down the problem to a single point of failure we can prevent from happening again. This reductionist approach of isolating a root cause and applying a specific solution provides us satisfaction. We feel in control, like we have conquered the chaos.
However, the reality is that most incidents in complex software systems do not have a single root cause. There are usually multiple interconnected factors in play. So, applying a simplistic solution fails to address the real issues and can even cause more problems later on.
In this post, we'll consider how to allow complexity in post-incident reviews and use storytelling to discover the details and share context.
Embrace complexity with Cynefin
The Cynefin framework (kuh-NEV-in) is a mental model for thinking about problem-solving. It can help you make decisions in complex domains—from your personal life to technical topics.
The framework categorizes issues into the following domains:
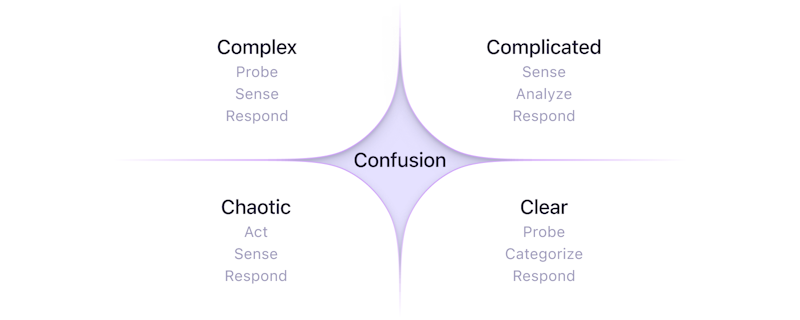
Cynefin framework
- Chaotic: Turbulent conditions that appear unrelated. You need to act to establish order before addressing the issues (Act → Sense → Respond).
- Complex: Situations with dynamic interdependencies and no right answers. You need to use your experience to probe and sense which direction to take (Probe → Sense → Respond).
- Complicated: Times when multiple factors require analysis to determine solutions. You can apply expertise and best practices to solve issues (Sense → Analyze → Respond).
- Clear: Straightforward cause-and-effect relationships with obvious solutions. You can just solve the problem (Probe → Categorize → Respond).
There's also a "confusion" category for when it's unclear which domain you're dealing with. You might start from confusion in the rush of an incident response. But by the post-incident review, you'll have enough context to categorize the situation.
Using these categories, you can label any situation that arises and follow the framework’s guidance on responding. Your response may solve the problem or move it down the list to a more straightforward issue to resolve. Rather than forcing everything to be a clear problem, this framework lets you see the complexity and address it appropriately.
Where do most software incidents land? Usually in the complicated or complex buckets, where quick fixes fail. These issues have ambiguity, uncertainties, and diverse perspectives. We need to resist the temptation to oversimplify and instead do the diligent work of investigating the complexity.
An example of working with Cynefin
Imagine, for a moment, that you're a Software Engineer working on a web app. Multiple customers have started complaining about degraded performance. Leadership is arguing over who is responsible, and there are no lines of communication open between teams or with customers.
That's a chaotic situation. Your first response should be to act to establish communication—start a new chat, create an email chain, or book a meeting room. Sense how this changes the situation and then determine your next move.
With all parties talking to each other, they agree on an action plan, so you can start looking at the technical problem. There's no obvious pattern to the failure from what you can see. You're now dealing with a complex problem. You start taking actions based on your experience and intuition to see how the system responds—looking for race conditions, checking environment details, etc. You learn a little more about what's going on with each action.
You identify a dependency between two services where one sometimes receives an unexpected value from the other. With a general area to focus on, this is now a complicated problem. You can apply your expertise to analyze the relationship between these two services to understand what's happening. In the analysis, you find a field sent from the first service with the type String, which is interpreted as a Boolean in the second service. Thanks to a malformed entry in the database, the first service sends a string that can't be interpolated as a boolean in that field.
Now, you're at a crossroads. There's a simple problem you can address first to solve the incident: fix the malformed value in the database. But there's also a complicated problem you might later tackle: avoid using String as a type for Boolean values.
Don’t force things to be simple
We all crave simple solutions. They make our lives easy. But looking for a root cause often encourages us to oversimplify a situation and think we've solved it when we haven't. This gives us a narrow view of the problem. It can also limit the creative problem-solving we do.
Consider a post-incident review for the example we just walked through. The issue relates to the usage of Duck typing, where the type (Boolean) is inferred based on its value. There are lots of ways you might choose to fix that issue, for example:
- Introducing strong typing.
- Adding automated testing to catch edge cases (such as property-based testing).
- Creating a constraint on the database table.
Those are all valid approaches and sensible actions you might take following the incident. But take a step back and ask: "Is that enough?" What led to duck typing instead of formally typing things in the first place? Did someone already try adding checks but ran into roadblocks?
Getting to the bottom of those questions is key. Your systems don't exist in a vacuum—they mesh with fluid business needs and users who can surprise you. It's tempting to trim away messy details to streamline things. But that big-picture view is crucial to noticing patterns and making informed choices.
So, by all means, fix the immediate issue! But have an open, nuanced chat about why it occurred and what else might be affected. Lean into the messy complexity instead of shying away. The answers you find will often be complex—and that's okay. Over time, you'll build up the experience necessary to navigate the complexity. Remember, the process for addressing complex issues is to use your experience to probe and sense which direction to take (Probe → Sense → Respond).
Harnessing the power of storytelling
How can we communicate clearly while retaining the complexity of a situation? With stories. Too often, we assume that technical communication requires simple, dry, data-heavy explanations stripped of any narrative elements. However, incorporating stories helps:
- Bring together different viewpoints.
- Build collective memory and understanding.
- Surface unseen connections and interdependencies.
- Provide context to ground abstract ideas.
By gathering and examining multiple first-hand accounts in the form of stories, we can start seeing meaningful patterns and make sense of the situation to determine the next steps.
Rather than trying to fill a template or complete some checkboxes in a post-incident review, use storytelling to paint a full picture of what transpired across teams and systems. Let themes emerge about gaps in test environments, assumptions made, oversight areas, and communication breakdowns. This will guide your solutions, whether process improvements, training, or improved coordination.
Resist the urge to create a narrative, but let it unfold from the different perspectives shared. If you create the narrative, you're limiting it to your perspective—instead, approach from a position of curiosity. You're not there to confirm your narrative. You're there to let the narrative form as the details emerge. Be curious about those details. Let the people who experienced it talk. When you don't understand something, ask questions. Probe down levels to understand what led to decisions and actions.
There's no standard way to achieve this, but there are some helpful frameworks, like the Five whys. The more you practice, the more you'll improve your pattern recognition over time and get better at asking the right questions to prompt helpful responses.
Improve your incident reviews
So, how can you become an expert at managing incidents and post-incident reviews? If you don't have decades of experience in the field, what hope do you have of recognizing patterns in the chaos of an incident?
The first step is to have an open mind. At this point, that phrase is such a cliche that it's almost meaningless. We all want to be open-minded, and most people believe they are. But in this context, being open-minded isn't about your state of mind. It's a practice.
After each incident or near miss—success or failure—ask yourself, "What could have gone better?” “What could have gone worse?" Ask your colleagues questions like "How did you find that information?” “What made you look at that dashboard?" If you can't figure out how someone came to a conclusion, ask them and then reverse engineer how someone might do it without all the institutional knowledge. Assume you are not dumb and have the same abilities as everyone else, but not always the same information.
The other practice is to read every incident report you can get your hands on. Allocate half an hour a week to reading them. Whether from Buildkite, Cloudflare, or an air crash investigation, read whatever you can get your hands on and write down three things you learned that could apply to your day job, or three things you think the report could've done better.
Good incident investigations read like a novel. They draw you in and make you want to read more. Buildkite is still on this journey of improvement, but our incident reports are public for you to check out:
We also recommend watching Nickolas Means' talk: Who Destroyed Three Mile Island?
Conclusion
By pairing the Cynefin framework and storytelling, you can allow for the messiness of reality while also having a path forward. This leads to incident responses that match the context, defuse chaos, strengthen team partnerships, and enhance the resilience of software systems over time. It requires patience and some comfort with uncertainty, but the payoff is sustainable solutions.
So next time an incident occurs, don't rush to judge or make knee-jerk fixes. Take time to unfold the narrative. Let Cynefin and stories work together to reveal the path forward. See where it leads you—it's likely somewhere unexpectedly fruitful.
Buildkite Pipelines is a CI/CD tool designed for developer happiness. Easily follow and decipher logs, get observability into key build metrics, and tune for enterprise-grade speed, scale, and security. Every new signup gets a free 30-day trial to test out the key features. See Buildkite Pipelines to learn more.




