On October 20th, 2025, customers experienced high latency and increased error rates across the majority of our services as a consequence of the major us-east-1 AWS outage.
Initially there was no customer impact and customers continued to run builds as usual. When traffic began to increase at the start of US business hours, our services were unable to scale up to meet the increased load as the AWS outage prevented any provisioning of additional server capacity.
The impact on error rates and response time varied between accounts, as our shards of compute capacity reached their limits at different times.
Impact details
All customers saw the Buildkite web interface experience latency between 17:00 – 19:20 UTC. During this time the error rate also spiked to 8%. Latency was 1.5 seconds on average, but some customers saw up to 7 seconds of latency.
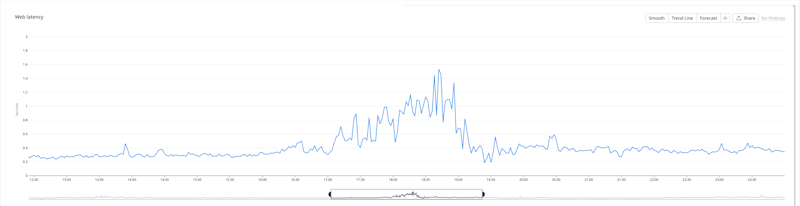
Dashboard latency during the incident
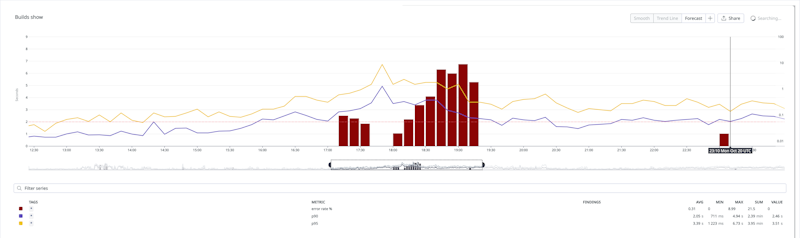
Error rates (with p90 and p95 latencies) during the incident
Customers experienced different impacts to both job dispatch and notifications due to our sharded architecture. These two latencies combine to form the core workflow that customers rely on.
The worst-affected customers experienced over an hour's delay in job dispatch times, combined with a notification latency of an additional hour between 13:00 – 20:30 UTC. The majority of our customers experienced only minor delays to job dispatch and notifications during this window.
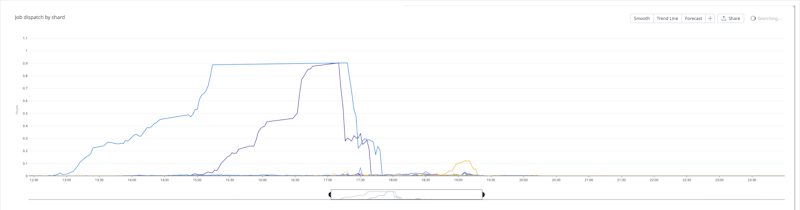
Job dispatch by shard during the incident
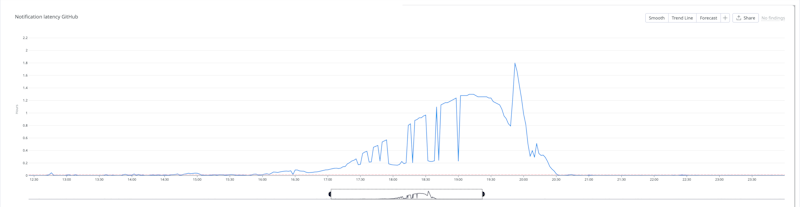
Notification latency during the incident
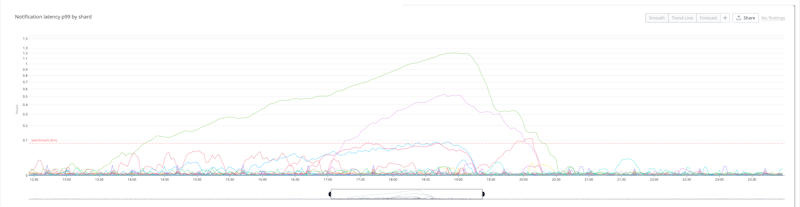
Notification latency (p99) by shard during the incident
Latency on the REST and GraphQL APIs increased between 13:00 – 16:30 UTC affecting all customers. Between 18:00 – 19:40 UTC error rates also increased to up to 10% of all customer requests.
This resulted in significant delays for any customers that depend on our public APIs to run jobs (api.buildkite.com and graphql.buildkite.com), such as those using agent-stack-k8s versions prior to 0.28 which uses GraphQL. Customers interacting with organisation and pipeline settings would also have been impacted by this latency.
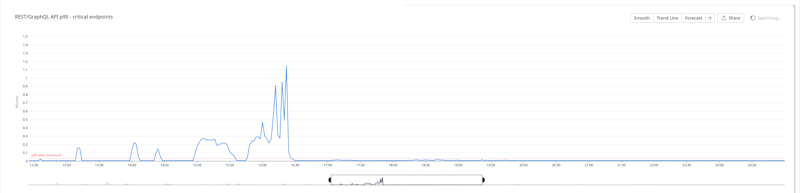
REST and GraphQL API latencies (p95) during the incident
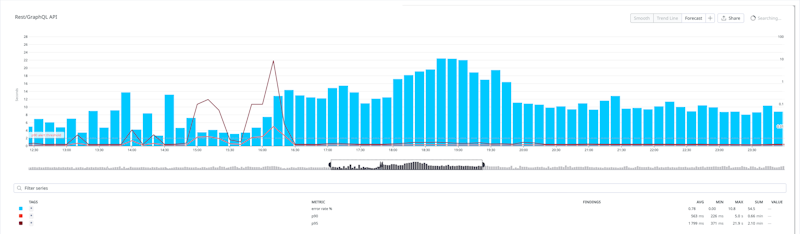
API error rates (with p90 and p95 latencies) during the incident
Incident summary
When we first became aware of the AWS incident, we paused all deploys to our production environment, in order to prevent scaling in and maintain our existing capacity. We preemptively opened a Statuspage incident to keep customers informed and escalated the on-call team. Many of our third-party communication and coordination tools experienced significant immediate impact which hindered our on-call team until alternatives could be shared.
Buildkite customer experience remained stable between 07:11 – 11:52 UTC and our on-call team stood down as AWS was reporting signs of recovery.
As more customers came online and began using Buildkite services, the EC2 launch failures in AWS prevented our autoscaling from increasing capacity to support standard workloads. Our sharded architecture meant that different shards were scaled to meet different amounts of traffic at this time.
From 13:15 UTC, Buildkite customers started to experience latency and increasing error rates to varying degrees due to the increase in traffic. Our on call team was alerted and began investigating. They opened a new status page to update our customers on the degraded performance.
From 17:00 UTC, all our available compute was in use and there was no further scaling possible. As a result, latency and error rates increased across all services and shards (particularly notifications and web traffic).
Between 17:10 and 17:52 UTC, we were able to shift some load from under-provisioned shards to an unused shard that we had scaled up for a load-testing experiment. Due to the length of the outage overlapping with peak Buildkite load, this mitigation was only viable for the first few hours before all shards were at maximum capacity.
Starting at 17:54 UTC, AWS allowed some compute to be provisioned at a severely limited rate. During this time we prioritized increasing capacity for the shards experiencing the worst impact.
By 20:36 UTC, all shards had returned to normal latency and error rates, and from 21:00, AWS stopped rate limiting our attempts to scale services.
All temporary load rebalancing was reverted by 01:32 on 21st October 2025 UTC.
Changes we're making
We are already investigating various avenues for resilience against region-wide events and ensuring we have backup avenues of communication in these major events.