Once again, the time has come to update some of the most critical of Buildkite’s infrastructure — our emoji support! ✨
Our last Emoji update was over a year ago, and added support for extremely important things like 🌯 burritos, 🦄 unicorns, 🐿 squirrels and 👍🏼 skin tones.
Since then, 🤳 Unicode 9.0 has landed, and shortly afterwards, 🏳️🌈 Emoji 4.0, each bringing with them a multitude new emoji and more opportunities to express yourself.
Buildkite now has full support for all of those characters, supports all of them in your device’s native emoji style, and all our custom emoji match!
In addition, we’ve polished up support for emoji sequences (groups of emoji which combine, Voltron-like, to form other emoji) like gender modifiers and the diverse family emoji.
This means emoji like “👩🏾🔬” (actually built out of 👩, 🏾, a zero-width joiner and 🔬), “👨👦👦” (👨, 👦 and 👦, zero-width joiners in between) and “👩👩👦” (you might have guessed it — it’s joiners in between 👩, 👩 and 👦!) now work correctly.
The rocky road to Emoji 4.0 support
Updating our emoji ended up being a more involved process than I anticipated. Buildkite’s emoji support was fully custom 🙀, so we didn’t automatically get support for new emoji features when users update their OS — instead, updates required us to update our own emoji infrastructure.
In early May, the provider of emoji information and graphics we rely on, Cal Henderson’s emoji-data, updated with Unicode 9.0 support. After seeing that update, I quickly put together updates to our infrastructure to make use of it.
This involved retooling our Unicode emoji replacement regular expression to handle all the new emoji. After researching several available options, including generating our own regular expression based upon our emoji catalogue, I chose the fantastic emoji-regex for the Javascript implementation, and the unicode-emoji gem as the Ruby counterpart.
The pull requests were reviewed, double checked, and pushed to production. I looked around at our emoji-filled pipelines on production. Things looked good!
But things were not quite so good…
That time I broke everything (with emoji)
After being live a couple of hours, I noticed in our Support Slack that some people were experiencing some issues loading job log output from Buildkite. I was the only person online, so I quickly checked on our infrastructure. Nothing looked especially broken, but I was seeing what appeared to be slightly higher load on our infrastructure than usual.
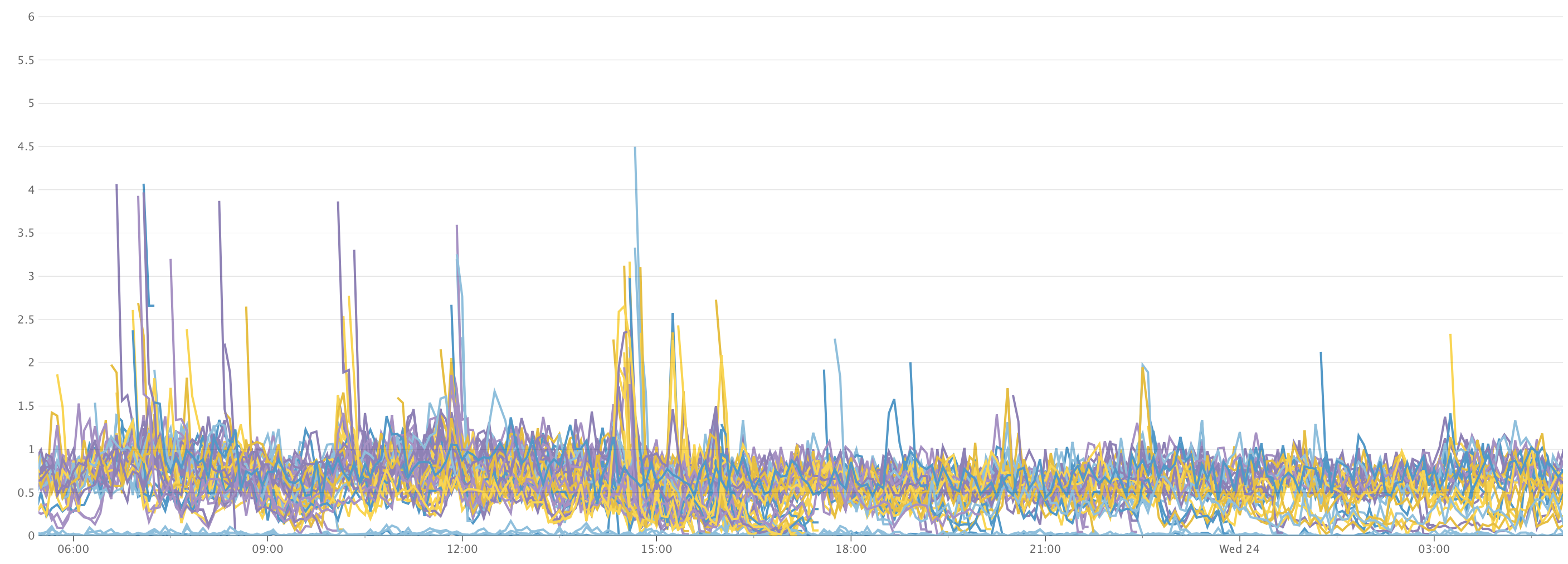
It turned out that the emoji updates were the problem. The new regular expression was slowing job log processing to a crawl. I didn’t notice the higher CPU load because our automatic load balancing had simply spun up more machines to handle it, and the graphs I was looking at charted CPU load per machine! 😅
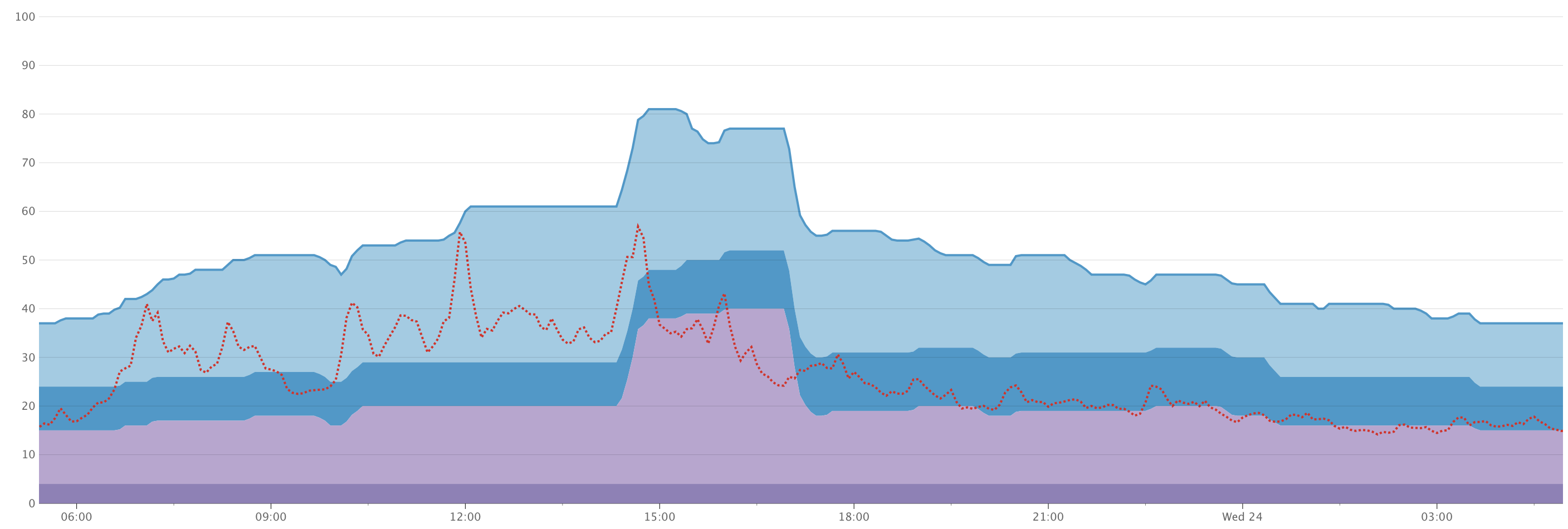
The changes were quickly rolled back so they could be reviewed.
Benchmarking Emoji for Fun and Bug Fixes
The first thing I did was check how much of a performance impact the changes had. I quickly whipped up a benchmark against the original code, and compared it to my updated code.
It demonstrated a 99.4% performance decrease. Ouch.
It turned out that the large increase in emoji complexity was causing our replacements to take a lot longer to process.
The changes include handling for over 700 new emoji, as well as updates to the handling of diverse families, which are made up of several characters each. The regular expression thus has to handle multiple permutations of many of these emoji, along with their placement in those sequences.
Looking at the changes, the first thing that stuck out was the regular expression itself.
The regex I had settled on for the Ruby side of things was actually a concatenation of all known emoji characters and permutations, in one big regular expression “or”. This meant that the regular expression was as computationally complex as is possible, as it has to check every single possible emoji character or sequence which exists!
The regular expression on the Javascript side, however, was more optimised. Instead, it’s instead able to skip emoji sequences as soon as the first character is not that sequence’s first emoji!
A tale of several character encodings and two regex engines
My first instinct was just to copy the regular expression the front-end uses, which I knew to be accurate and fast, but unfortunately it isn’t compatible with Ruby’s regular expression engine! This, it turns out, is because of our old friend text encodings!
Javascript’s strings are encoded using UCS-2, an encoding very similar to UTF-16, which meant that astral plane characters like emoji are actually encoded as two or more characters each (known as surrogate pairs).
In Ruby, on the other hand, every string is UTF-8, which handles multi-byte emoji as a single character. Given that emoji-regex targets Javascript, it handles those UCS-2 surrogate pairs, and Ruby doesn’t understand them.
My first attempt to work around this was performing regular expression replacement on emoji-regex’s regular expression, attempting to replace these surrogate pairs with their UTF-8 counterparts. As it turned out, my approach was too naïve to handle the optimised regular expression because emoji characters are referred to using ranges of surrogates, and accommodating this in a regular expression would require a lot of work!
So I shelved that approach, and started looking into whether I could produce a true equivalent to emoji-regex in Ruby.
Teamwork rules ok
While I weighed our regular expression options, Samuel investigated improvements to the emoji parser itself.
He discovered that it had been engineered to loop over each emoji found in the processed text several times in order to replace all the emoji we handle, which was quite inefficient!
He updated the logic to only run a single replacement pass, which improved performance to roughly ten times the previous performance!
A fractal of yaks
Digging into the workings of emoji-regex, I found that it coaxes a data set provided by the unicode-tr51 package into a single regular expression built out of Unicode properties.
The regular expression is processed and optimised by a combination of the regexgen, regenerate and jsesc npm modules.
Looking into them, I found that regenerate and jsesc can be set to generate UTF-8 output, but neither regexgen nor emoji-regex exposed such an option. UTF-8 regular expressions are newly supported in ES2015, so it might be useful for the option to exist for Javascript too. This looked like the path forward!
I quickly put together proof of concept patches, took their output and pasted them into our Ruby code! Ruby still wasn’t happy, but it turned out to be an easy fix.
Javascript supports \x escape codes to specify two-byte character codes. Ruby, only allowing UTF-8, requires four-byte \u escapes. Rewriting the handful of \x escapes in the regular expression to \u00$1 meant that I now had an actually-equivalent regular expression for Ruby!
At this point, I evaluated the relative performance of the new emoji. It was better than the original, but only by about half. We were still losing a significant amount of performance to this processing.
How I learned to stop worrying and let the device handle emoji
I had originally intended to quietly ship this update before pushing to remove our custom handling of Unicode emoji, so I wondered if this crisis was exactly the opportunity I needed.
I hypothesised that most modern OSes and devices have sufficient emoji support that custom handling was unnecessary. Examples like GitHub backed up this hypothesis! GitHub’s approach hinted at a slightly more complex answer, however — different browsers handle emoji differently!
I put together a test for this on Codepen. You can check it out in your own browser now!
My research shows that a majority of browsers display emoji slightly larger than text, by a factor of roughly 1.3. An important minority of outliers, though, (Chrome and Firefox on macOS) display them at roughly the same size as the text!
This presented an interesting challenge, given we have our own custom, image-based emoji set. Either we’d need to scale up the Unicode emoji on these outlier browsers (GitHub’s emoji do this!), or scale our custom ones to match.
Scaling the Unicode emoji up wouldn’t do anything to work around the performance penalties we were facing — we’d still have to be searching text for these characters, and replacing them with something else.
The path of least resistance
To detect the scale in the user’s browser, I updated my browser emoji support toolkit mojibaka to measure a browser’s emoji display via its new detectScale method.
With this knowledge and new tool, I set about styling our custom emoji. The output of mojibaka’s detectScale method is best used as a guide, so I styled up a default emoji size of 1.23em for the majority of browsers, and added an override class to the document for browsers with smaller emoji rendering.
This gave precise control over the emoji behaviour, and after some time spent tweaking the sizing to look correct in all the major browsers across several systems, I published my new pull request. The new changes looked good, and we managed to significantly simplify the emoji processing on both the front- and back-end of the application, as well as significantly reduce the amount of emoji data sent to the client!
I also pushed patches upstream to both regexgen and emoji-regex to expose ES2015 style regular expressions from each.
Building upon both of those, I then published the emoji_regex gem, which we now use to process Buildkite’s emoji catalogue!
A quiet but important change
Other than a minor bug involving localStorage access being blocked 😅, the new emoji change was launched without a hitch. I’m really proud of the much, much simpler approach we’ve now got to this!
As the set of emoji people expect to be able to use grows, so too will the burden on any custom handling, and the more you should consider just letting the user’s device handle them! And if their device can’t, you can always suggest they install the fantastic Symbola font. 😜
Over the course of producing this update, I learned far more than I expected to about emoji, Unicode, Javascript and Ruby. And I’m glad to be able to say that we’re fortunate enough to have found that we don’t need custom handling. ☺️