You return from lunch and request a change to a core monorepo, and so do 50 other engineers. There's a big change at the head of the queue that will take a few hours to test. None of the other 49 changes (including yours) can proceed until the big change lands.
How would you validate and land the changes in minutes instead of hours? The engineers at Uber faced this challenge.
Xioayang Tan and Tyler French are Senior Software Engineers in Uber's developer experience team. At Unblock22, they shared Uber's journey to reduce the monorepo build times by 50% and provide flexible, scalable Continuous Integration (CI) for thousands of developers.
Uber's Go monorepo
Uber writes most of its back-end services and libraries in Go. In 2018, they launched the Go monorepo using the open-source build system Make in combination with Go's go build. Early adopter projects saw an immediate improvement in build efficiency compared to the polyrepo approach. As the monorepo matured, Uber moved more and more projects to it, and usage expanded rapidly.
Eventually, the team upgraded from Make and go build to Google's Bazel. Bazel understands how each target is built and how they relate to each other, including the repository's source files. The build dependency graph (build graph) allowed Uber to optimize their CI workflows. The CI system didn't have to validate the entire monorepo every time a developer made a small change, like updating a readme. At the other extreme, it knew what to check when someone changed a fundamental library. (Fun twist: Bazel is built on top of Buildkite.)
By 2022, the Go monorepo was the largest code repository at Uber:
- 50 million+ lines of code
- 500,000+ files
- 3,000+ engineers working on it
- 1,000 commits per day
With so much activity in one repository, how did they support safe and fast changes?
Keep main green at scale
The team was working on a new version of Uber's mobile app for riders. Leading up to the launch, engineers were landing hundreds of commits every few minutes. The changes were passing automated tests, but collectively they resulted in a substantial performance regression. Senior engineers spent several hours bisecting the mainline, trying to find the changes to roll back. New commits further aggravated the situation, leading the team to block changes to main while the investigation continued. The launch was postponed.
How could they ensure the Go monorepo was always in a shippable state?
Uber built a system called SubmitQueue to keep the main branch green while landing thousands of commits per day. SubmitQueue is like GitHub's merge queue for CI builds. Check out Uber's blog posts and conference paper to learn how it works.
| SubmitQueue Advantages | Challenges |
|---|---|
| Guarantee the main branch is always green. | High volumes of CI build traffic. |
| Validate changes in parallel, including all build steps. | Large changes caused turnaround times in the order of hours, not minutes. (SLA? What SLA?!) |
| Land changes out of order with confidence. | |
| Support a range of scenarios with different tolerances for risk, testing rigor, and turnaround time. | |
| Provide internal service-level agreements (SLAs) so developers know how long they need to wait for changes to be merged into the mainline. |
SubmitQueue interfaced with Bazel and improved Uber's workflows and productivity. It worked well for small changes, but large changes were taking too long to process, blocking others later in the queue. Developers were waiting hours for their changes to land.
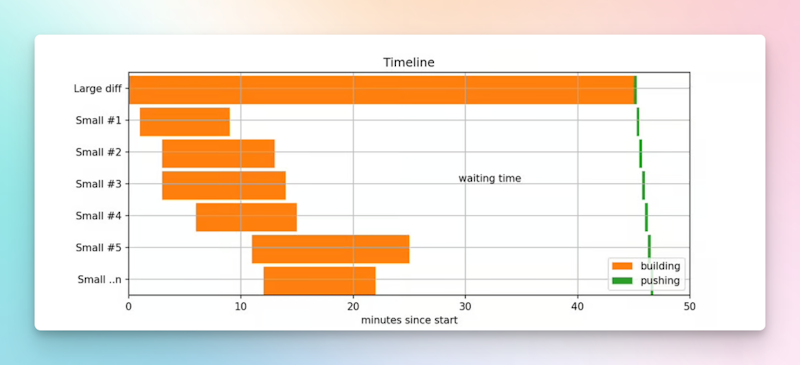
Timeline showing increased land time for smaller diffs waiting for a large diff.
Xiaoyang, Tyler, and the team formulated a three-step plan to tackle the problem:
- Optimize SubmitQueue.
- Keep large changes out of the queue during peak hours (an unpopular but temporary fix).
- Make the build and test faster.
We won't cover SubmitQueue here, but you can follow its evolution in Uber's blog posts about improving build times and bypassing large diffs.
Step 2 was an interim measure to improve productivity while they worked on a topic dear to our hearts: making builds faster. We cover that next.
Investigate and address the sources of CI slowness
Uber identified the main steps in their CI builds, which executed in sequence:
- Prepare the build environment.
- Run pre-build checks.
- Linting checks.
- Resolve dependencies.
- Identify which Go packages have changed and require validation (Uber's Changed Targets Calculation, CTC).
- Build and test the changes (Bazel).
- Analyze the outcome and report back to the engineer and related systems.
Dynamic builds and parallel jobs
Uber’s platform team asked themselves: What steps could run in parallel?
The build and test was the most time-consuming phase and needed the changed targets calculation to proceed. However, they could use the CTC output to split up the changed targets and run them in parallel on separate machines or hosts.
Here's the catch: Uber was using Jenkins at the time.
Jenkins executed a bunch of scripts in order—it was linear. They used the Multijob plugin to execute some tasks in parallel, but the plugin's job hierarchy was static. The engineers pre-defined 50 parallel job shards, with each launched depending on the metadata (including exit codes). This approach created the illusion of dynamic sharding. They could run 10,000 targets in 10 minutes instead of 60 minutes.
The sharding strategy worked, but it lacked the flexibility to change or scale as the team's needs evolved. Hacks in the bash script made it difficult to introduce further complexity without breaking something. They relied on string manipulation and passing variables around to achieve the desired effect. As Xiaoyang observed, it quickly became a pain point.
Further improvement would require truly dynamic CI, where the Uber team could define each build and its configuration at runtime. For example, if the Changed Targets Calculation (CTC) returned zero, they could skip the build/test step completely. If a change affected one target, they could run it in one shard. If a change affected hundreds of targets, they could expand beyond 50 shards without having to set them up ahead of time.
Replace Jenkins
Uber embarked on the evaluation process to find a successor for Jenkins. Senior Staff Engineer Yohan Hartano outlined the top 3 requirements:
- Dynamic scalability.
- Flexibility to support Uber's evolving CI strategies and processes.
- Run and manage a mix of on-premises and Amazon Web Services (AWS) hosts.
A proof of concept demonstrated that Buildkite delivered all three, along with quality-of-life improvements:
- New reporting capabilities to monitor test flakiness and build reliability.
- Easy to use plugins.
- Developer-friendly interfaces.
With support from Buildkite's Solution Architects, Uber committed to migrate from Jenkins and made the switch.
Set up dynamic pipelines with Buildkite
Xiaoyang and the team used Buildkite's pipeline upload step to define their builds dynamically, using scripts from their source code.
Their "main" step kicks off the workflow by running their CTC algorithm to calculate what Bazel targets have changed, which informs the steps needed for the build. The Uber team can:
- Trigger parallel jobs.
- Run informational steps with non-blocking soft fails.
- Upload artifacts (like tracing profiles and error logs for debugging).
- Upload files to support inter-step interaction.
- Create as many shards as they need for a given step.
- Use different sharding strategies for different kinds of targets (sharding size, queue sorting).
- Annotate builds with internal links for easier code review.
- Use a Golang CI runner instead of bash and extend it with Go functions and unit tests over time.
Containerization and performance
The Uber team was eager to introduce containers to their CI workflows. Containers would give each monorepo team more control over their CI environment and isolate their work from operational activities like upgrading machine fleets and operating systems.
Uber started out with Buildkite's Docker plugin to pull the image, run a Docker container on the host, run the scripts, start the Bazel server, do the rest of the work, and exit. The plugin tore down the container, along with the Bazel server and the memory footprint. The process repeated for every run.
Buildkite allowed Uber to run each shard of each step in a separate container, with a separate checkout of the repository.
The turnaround time for the larger (slower) builds improved (P99, P95), but the 50th percentile (P50) and average time increased due to the overheads introduced by containerization. The bottleneck shifted left from validating the changes to setting up the jobs:
- Checking out a repo of 500,000 files is slow.
- The containerized builds were not aware of each other and duplicating work.
- Bazel is slower on ephemeral servers because they're cold.
- Mounting on-disk dependency caches to share across runs helped, but only a little.
How did Uber address these bottlenecks?
- Make Git checkout faster.
- Create persistent container environments.
- Use host and remote caches.
Git checkout
Uber created a Git snapshot that could be downloaded quickly to the machine before checkout. Each build refreshed the index with the snapshot, instead of manually checking out the repository. The build would only need to fetch commits made after the latest snapshot. Uber's approach reflects recommended practices for monorepos.
Reuse containers (stateful CI)
Xiaoyang and the team reconfigured their jobs to reuse containers when certain conditions were met, delivering warm server performance gains and reducing the setup overhead.
To identify each container, they assigned a hash sum and labels. This allowed them to match jobs to containers by criteria like job name, Bazel version, image hash, agent IDs, content of Docker Composer files, and environmental variables.
This led to the Goldilocks question: How do you keep a container running long enough for Bazel to warm up, but not so long that it goes stale?
The team exploited the lifecycle of Buildkite agents. When they see a new agent on the host, they know it's time to tear down the containers and start over.
Of course, they could also force new containers to spin up for Bazel upgrades and image updates.
This orchestration delivered 30% performance gains for Bazel queries and found the sweet spot for warmth vs. staleness. The CTC runtime improved by 60%.
Caching
In addition to the Git snapshot, the Uber engineers implement two other types of cache to boost performance:
- Static, read-only dependency caches on each disk to share across containers and jobs.
- A Bazel remote cache to share build outputs.
The on-disk caches are refreshed periodically by a Buildkite job that uploads them to remote storage. The first job on the host downloads the cache.
Uber's system calculations avoid building the same target on multiple shards, but sometimes it's unavoidable. Root targets assigned to different shards may need the same package. Sharing the Bazel build outputs eased that bottleneck by allowing subsequent shards to reuse rather than rebuild the package.
With this setup, Buildkite could build the entire monorepo in less than 25 minutes.
Better developer experiences
Buildkite delivered immediate improvements to developer happiness and productivity:
- The accessible, intuitive user interface (UI) gives Uber engineers a clear, full picture of their pipelines and workflows. It's easier to find jobs and check on build status.
- Logs are stored and retained in a central location. Uber's Jenkins logs were spread across many machines and were rotated to conserve disk space.
- Managing log output is easier with Buildkite. Uber groups their logs, making them easier to read and decipher. They can debug a test from a month ago if they want to.
The new CI platform inspired Tyler and the team to make further improvements to the developer experience at Uber. With Buildkite, they:
- Run a shadow pipeline alongside production, so they can test features and new plugin versions.
- Prevent runaway builds with new monitoring and alerting (and improve build metrics).
- Support user-defined jobs.
- Automate dependency management.
Let's explore the last three in more detail.
Improve visibility with pull metrics
Uber uses the Buildkite API to monitor build events and capture metrics. For example, they calculate build duration from the build start and finish events. They set up alerts on build failures.
Along the way, they discovered runaway jobs that were getting stuck and taking a long time to fail. The team wanted to identify the stuck builds much sooner, so they designed Uber's Buildkite Prober.
The Prober is a separate service that queries Buildkite to generate pull metrics. It makes API requests once per minute, analyzes the data, and helps Tyler and the crew report back to developers. The service informs:
- Individual developers via direct reports
- In-house dashboards
- Metrics and alerting systems
- Logging databases
Instead of waiting for a stuck build to fail, the system alerts them to slow jobs so the on-call team can investigate in real-time. They can check on agents and monitor the Buildkite API. In the future, they will extend it to classify failures and perform artifact analysis.
Monitor agent health
Uber tracks build failures as a sign of agent and host health issues. Sequential agent failures are easier to interpret than diagnosing host and hardware issues.
The Prober helped the team identify that their Go builds rarely failed more than three times in a row on one agent. They used that data to set thresholds for taking agents out of rotation.
Support user-defined jobs with extensible CI
As part of the developer experience team, Xiaoyang helps developers set up custom jobs. They include:
- Periodic tasks.
- Post-land jobs that run on every commit.
- CI jobs triggered by code changes.
- Ad hoc tasks run from the command line.
Buildkite allows the team to support all of these use cases without creating hundreds of extra pipelines. Tyler's team created a Domain Specific Language (DSL) and a config parser to upload custom scripts as a dynamic step in the build process. The runner is the only static piece of code, and it works for the 200–300 use cases.
For example, here’s a developer’s custom job in their DSL:
# my-job.yaml
owner: uber team
agent:
queue: test-ci-prime
env:
var1: abc
var2: 123
service_auth:
uber.com/reservation
uber.com/airportThis gets translated to Buildkite’s pipeline steps like so:
# pipeline.yaml
steps:
- name: my-job
key: my-job
command: my_script.sh
agents:
queue: test-ci-primeReviewing the outcome of your custom job is easy: Buildkite allows Uber to filter by job key or other metadata to see the pass/fail status. A developer can look up their job in the Buildkite interface or access the information via the API.
Automate dependency management
Buildkite helps Uber manage their third-party dependencies. They have more than 2,000 dependencies for the Go monorepo, let alone other languages and systems used at Uber. If they're maintained manually, unowned dependencies become stale, unhealthy, and maybe even a source of vulnerability.
Tyler's team recognized it would be too slow and time-consuming to maintain 2,000 dependencies actively, so they created a "green-keeping endpoint" (pipeline) in Buildkite to automate the work. They provide the list of dependencies to Buildkite, which in turn checks a version registry to check for new versions. Uber uses a few, including GoProxy the Go monorepo, NPM, and Maven for Java.
Dependency upgrades are sharded, so it's possible to make 200 concurrent upgrades in as little as 5 minutes. Uber's shared cache strategy speeds up the checkouts, minimizes the compute power, and minimizes the impact of go mod tidy's network requests.
Tracking the outcome of hundreds of dependency upgrades is no small task. Tyler and the team created a service to track which upgrades pass and fail, making it easier to assign downstream tasks.
The green-keeping endpoint also accepts user-initiated upgrades via the command line. To upgrade Golang's x/crypto package, a developer can use the command line to kick off the Buildkite workflow:
upgrade golang.org/x/cryptoConclusion
You return from lunch and request a change to a core monorepo, and so do 50 other engineers. Your change affects the entire repository, but you can land it within 15 minutes. You're happier, and your team's productivity is better than ever.
A solution to one challenge can introduce a new one. Uber's monorepo journey demonstrates the power of dynamic CI and the value of continuous improvement. Sincere thanks to Xiaoyang and Tyler for sharing their experiences—we hope you enjoyed the ride.
If you’d like to learn more about scaling CI/CD for monorepos, check out the following resources:
- CI for monorepos
- How to build CI/CD pipelines dynamically at runtime
- How Bazel built its CI system on top of Buildkite
You can dive into more of the details at Uber by watching their webinar with Buildkite:
You can also read their blog posts and papers:
- How Uber halved Go monorepo CI build time
- Bypassing large diffs in SubmitQueue
- Building Uber's Go monorepo with Bazel
- Keeping master green at scale (EuroSys 2019)
Buildkite Pipelines is a CI/CD tool designed for developer happiness. Easily follow and decipher logs, get observability into key build metrics, and tune for enterprise-grade speed, scale, and security. Every new signup gets a free trial to test out the key features. See Buildkite Pipelines to learn more.