The importance of Kubernetes (K8s) in the container ecosystem is undeniable. If you’ve seen the benefits of using Kubernetes to host your production workloads, you might now be considering using Kubernetes to also host your CI/CD workloads, too. And that means working with containers in containers.
You’re probably already using Docker containers in CI/CD. That’s usually relatively easy to understand, given the build ecosystem is likely a VM-driven environment. The Docker socket is readily available to spin up containers that are built with their own operating systems, and containers can download packages without having to interact with things outside of their environment.
In the shared compute environment of a Kubernetes cluster however, builds no longer execute in isolation. A lot of activity is happening in nodes: they’re being spun up and torn down. Build caches are no longer in the file system as they once were—they’re far more dynamic. This dynamism is what makes Kubernetes so great at running web-scale services, and orchestrating components across regions and zones. But when it comes to builds, it’s essential to have ready access to the data you need for use in CI/CD processes downstream so builds execute as fast as possible. And that’s the challenge, along with the complexity of containers in containers.
In the world of containers in containers and Kubernetes, there are so many levels of abstraction, and even more ways to build your environments and container images. In this blog, we’ll look at some of the main options:
- Docker in Docker
- Buildpacks
- Kaniko
Docker in Docker (DinD)
Docker in Docker (DinD) is exactly what it sounds like—running Docker within a Docker container. DinD started because the Docker team needed a way to Develop Docker itself. But since then, teams have used it in CI/CD. The self-contained, disposable environments lend themselves well to building, testing, and deploying applications–but there are some significant gotchas to be aware of.
Benefits
Because Dockerfiles are a scripted approach, the content in a Dockerfile explicitly defines how to build your container. Dockerfiles are well-understood and a common pattern to follow when developing containerized applications. Your dev team can keep their existing tools they’re familiar with, and your CI/CD system can take advantage of the ephemerality and speed of container based agents (a.k.a. workers).
Considerations
The inception-style outer-Docker and inner-Docker can lead to confusion and clashes between security profiles—an incredibly complex issue to debug.
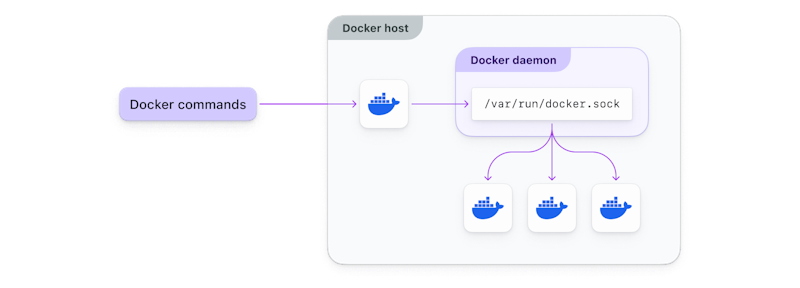
When getting started, you’re likely to run into an error like this:
Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
That’s because you’re running docker-in-docker without providing access to the socket. Remember, you’re now trying to build an image inside a container, rather than a VM, and that container has less direct access to the system and its resources.
Using a Kubernetes sidecar is one way to access the socket in Docker. The sidecar container design pattern allows you to run an additional container alongside your main container in the same pod. The sidecar container can perform tasks that complement the main container. It shares the same lifecycle, resources, and network namespace, but has its own file system and process space. This sidecar container has access to the same ports, volumes, and environment variables as the main container but cannot interfere with its execution. While there’s some separation of concerns, providing privileged access to the Docker socket in a container like this has security implications you should understand well, or discuss with your security team.
securityContext:
privileged: true
allowPrivilegeEscalation: trueIf a malicious container or even a container not fully understood was run in CI, it could take advantage of this escalation of privilege attack vector.
You probably also want faster build times, so you’ll need to look into smart layering, caching, and possibly even multistage builds. There are some hefty performance overheads to consider, and this is where the complexity of building docker images from inside a docker container can rear its ugly head.
Learn more about Docker in Docker and Sidecars
- Do not use Docker in Docker for CI
- Kubernetes sidecar containers
- Building Docker images from inside a Docker container with a Kubernetes sidecar
Kaniko
If you’d like to stick with the Dockerfile-driven approach without the security or performance overheads, Kaniko is a popular open-source project that allows you to build container images from a Dockerfile. It’s perfect for customized and complex Dockerfiles, or if you need to containerize projects with multiple programming languages.
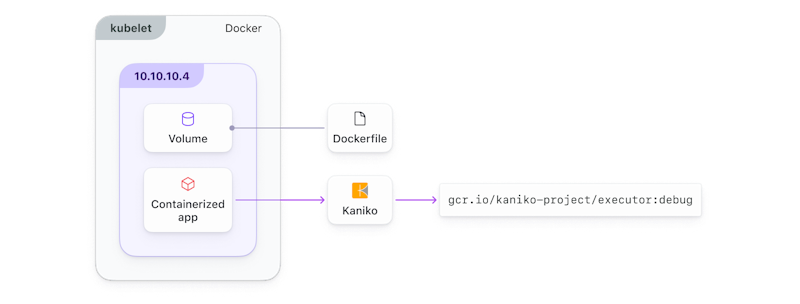
The Kaniko container builds the Docker image from instructions in the Dockerfile
It simply provides a Docker image that can run as a container for local development or testing, or on a Kubernetes cluster. In CI, the kaniko container builds your docker image based on the instructions in your Dockerfile.
You won’t need to provide privileged access to the Docker socket, so you can avoid the security risks that docker-in-docker can pose. Kaniko uses a distributed build process, and each step of the build process is executed in a separate container, which means Kaniko builds images without requiring privileged access to the Docker daemon.
It’s also significantly more performant than Docker-in-Docker. Caching is challenging in Docker, as changes to any layer will invalidate the entire cache for that layer and subsequent layers. Kaniko provides an efficient cache management system where only the necessary layers are invalidated, leading to better cache utilization and faster builds.
Considerations
There’s not a lot that Kaniko can’t do, provided you’re building fairly basic containers. If you need to do more complex things, like creating multi-architecture manifests, for example, you’ll need to use other tools to combine separate builds into a single manifest.
Learn more about Kaniko
- Getting started with Kaniko tutorial
- Building container images from a Dockerfile on Kubernetes with Kaniko
Buildpacks
Buildpacks was created by Pivotal and Heroku in 2018 and is now an official CNCF project. Buildpacks is a centralized, automated solution that builds Docker images from code without needing a Dockerfile.
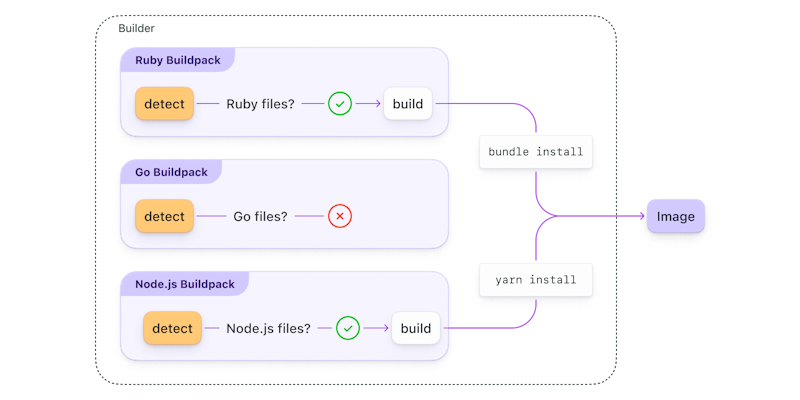
Each Buildpack inspects the application source code to detect if they should participate in the build process. If they should, they build the image.
Buildpacks encapsulate a single language ecosystem toolchain, and individual buildpacks can be composed into a collection (called a builder). In the builder, each buildpack inspects the application’s source code to detect if it should participate in the build process. If it should, it goes ahead and builds the Docker image.
Benefits
Running pack build with the Pack CLI will create a Docker image from the source code. Buildpacks can be written in any language, and completely customized with features allowing for buildpacks to be included inline in source code, build time environment variables, and image extensions in Dockerfiles.
You can implement smart caching using metadata from previous builds to skip steps if a buildpack determines something hasn’t changed. Because caches are isolated to individual Buildpacks, you can create tailored read/write volumes that mount different things like your Go dependency cache, your Python cache, or your Ruby cache–meaning some can be more dynamic than others. For example, your Go runtime cache might be accessed less frequently than your Go dependencies.
The goal of Buildpacks is to create reproducible builds that produce the same output from the same input when a container or other artifact is built. Reproducible builds mean you can avoid unnecessary container layer rebuilds. They also satisfy a requirement for Level 4 of Supply chain Levels for Software Artifacts, making Buildpacks a great choice if you want to improve the security of your supply chain of container images.
Buildpacks automatically generate a Software-Bill-of-Materials (SBOM) in CycloneDX, Syft, or Spdx format for each Buildpack. Each SBOM captures timestamped records for every package and component used in the image build process. Metadata can be exported using the Pack CLI by running pack sbom download your-image-name.
Considerations
Buildpacks is a super powerful, extensible tool if you can create and maintain an ecosystem of buildpacks. It lends itself to multi-language support, and composability of buildpacks, and is secure by design.
There can be a steep learning curve as you’ll need to consider your pack lifecycle caching strategy. But, because Buildpack caches are isolated from each other, different caching can be used—for example, runtimes vs. dependencies.
Learn more about Buildpacks
- Getting started with Buildpacks tutorial
- Cloud native Buildpacks VS Dockerfiles for building container images
- Building containers on Kubernetes with Buildpacks
Conclusion
Having your developers write and work with Dockerfiles is natural, even easy in many cases. Maintaining those Dockerfiles for complex build environments in Kubernetes takes more time and effort than you might expect. But not all is lost, there is hope! We’ve shared a number of alternatives that help you wrangle the challenges of building Docker images in your containerized CI agents hosted on Kubernetes. They each have their tradeoffs and suitability for certain environments, but hopefully this blog helps you make a well-informed choice.
Docker-in-docker vs. Kaniko vs. Buildpacks:
- Docker-in-docker has a low barrier to entry–but handling caching and security can quickly become very complex.
- Kaniko is perfect if you’re keen on a Dockerfile-driven approach to building containers in containers in Kubernetes but have hit the limits of what you can achieve in DinD. It’s far more flexible and performant than DinD and is great for multi-language projects and complex Dockerfiles that require heavy customization.
- Buildpacks is the answer for avoiding snow-flake Dockerfiles for each application in favor of a centralized, adaptable solution that builds containers from application source code.
Check out Building containers on Kubernetes—how to get unstuck to see demos of Docker-in-Docker, Kaniko, Buildpacks, and more.
No matter what approach you adopt, there are tradeoffs between effort and extensibility. May your builds be stable and speedy, whatever strategy you choose.