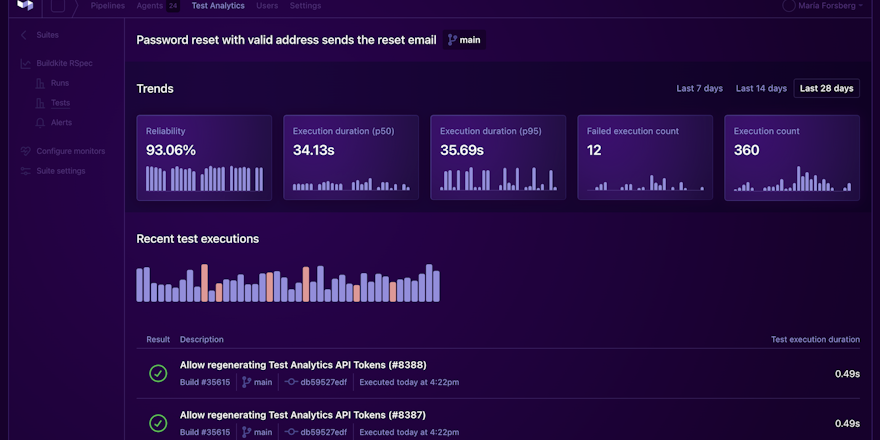
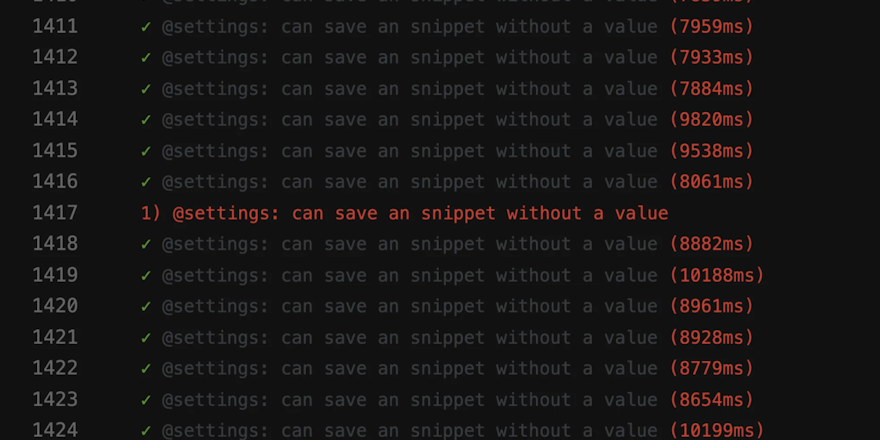
If there’s one thing that’s made our customers like Airbnb, Uber, Elastic, and Slack successful, it’s that they aggressively drive build times down. This is at the core of the Delivery First mindset: the idea that when you can deliver software just as easily as you can write it, you can test out new ideas and react quickly. It’s how the best out-innovate the rest.
If you work in software you know viscerally that testing takes up the majority of build time. That’s why the best companies therefore spend a lot of time and effort optimizing their test suites, where the biggest gains are to be had. We’ve had the unique opportunity to peek behind the curtain at these engineering organizations; we’ve seen first-hand the winning best practices they use to test code at scale and keep build times almost impossibly low.
Here’s what we’ve learned.
Testing is a balancing act
Testing code is about striking a reasonable balance between confidence and speed. The most successful companies get this right at a massive scale, allowing them to keep delivery times low and engineering morale high—and ship high-quality products fast.
How we got here
Let’s take a step back and look at how testing has evolved over the past decade. Not so long ago, specially dedicated teams wrote “automated test suites” for software. This had some advantages. The core components of a product were tested by people who specialized in just that—writing tests. But it also was part of the (at this point ancient) “waterfall method” of software development where requirements were thrown over the wall, resulting in shipping delays, miscommunications, and siloed development.
Few roles like “automated test engineer” exist anymore because the software world has shifted to a model where engineers write their own tests for the software they develop following models like test-driven development (TDD). Setting aside the still-integral role of QA teams that run integration tests or manual tests, the vast majority of tests today are unit tests written by developers for their code.
Key word being “vast”: the shift of responsibilities in testing has led to a balloon in the volume of tests at any given organization. And it’s only compounding. With the rise of AI-assisted coding, engineers are using AI tools to generate tests instantly—meaning the cost of writing a test is approaching zero.
Is that a good thing?
More tests != better outcomes
The goal of testing is to increase your confidence in the quality of the end product. That’s why tracking test coverage is a best practice, and you will rarely hear anyone advocate for fewer tests.
But more testing comes at a cost. You’ll spend more compute time running tests and more human time maintaining your test suite and tracking down and fixing unreliable and flaky tests.
Arguably the greatest cost is build time. Because testing can take so long, it can wreak havoc on your build metrics if you’re not careful.
Our customers manage to achieve high-quality products and fast delivery by testing smarter. Here are the three secrets to success:
- They remove tests that have aged out. They may even run non-critical tests post deployment to keep builds fast.
- They run tests in parallel using test splitting. Buildkite’s solution provides unlimited concurrency and optimized load balancing across agents.
- They take an uncompromising stance toward eliminating flaky tests.
As flaky tests can have widespread impact—especially with large monorepos and complex merge queues—we will spend the rest of the blog on this topic.
The flaky tests problem
If you’ve ever been woken up by a late-night email to learn an infamously flaky test has blocked your code from making it into the main branch—which you probably have—we bet you don’t need much convincing that flaky tests are a problem. While flaky tests might be merely annoying for a small team, they become truly debilitating as a company scales to hundreds of engineers.
Here’s why:
- They destroy trust in your QA process. A flaky test is arguably worse than no test at all. It may pass or fail based on any random event—for example, if a race condition occurs or if a shared cache is not reset in time. So even when the build is green, you’re left unsure whether there’s a bug with the end product. Software delivery shouldn’t operate on luck.
- They’re expensive. Flaky tests cost human bandwidth to find and debug, and resources to rerun test suites. This might not matter when your company is small, but for a giant monorepo where you’re running tens or even hundreds of thousands of tests for each build and some percentage of them are flaky, it adds up.
- They stall development. Engineering organizations of sufficient size tend to use complex pre-submit infrastructure with merge queues for checking in code. In this world, flaky tests have ripple effects, stalling large batches of changes and leaving dozens of unproductive, frustrated engineers in their wake.
- They slow down build times in unpredictable ways. Since flaky tests can cause multiple reruns of parts of the test suite, they can cause build time to balloon quickly. Playing whack-a-mole with flaky tests is a losing game and can prevent you from meeting a launch deadline or pushing a timely fix to customers.
- They hurt innovation. We’re not saying that flaky tests directly stop you from building the next market-leading product. But they do prevent you from getting a working product quickly into your customers’ hands so you can experiment, get feedback, and improve. These kinds of feedback loops allow you to compound your knowledge and deliver exponentially better products in each iteration.
Patterns from successful companies
Companies that prioritize delivery think about testing at a foundational level. Here are the techniques we’ve seen our customers implement successfully.
Best practices
Organizational best practices for writing and running tests can go a very long way. Delivery First companies:
- Enforce hard upper bounds on build times—say, 10 minutes for a change request to make it into production. This can act as a forcing function to tackle flakies as well as implement other optimizations (like an extensive feature flag system) to keep code quality up without slowing down delivery.
- Adopt a zero-tolerance policy toward flaky tests where they aren’t pushed off to fix later—there’s a clear approach to dealing with them (see the following points for ideas) that everyone knows and follows rigorously.
- Assign ownership for tests, since it’s often unclear who should work on a fix when tests become flaky—especially when two people’s tests interact in strange ways. This includes tracking and following up on resolution.
- Invest in tooling, whether in-house or third-party, since handling flaky tests at scale requires advanced systems that can (among other things) monitor test reliability and automatically quarantine flaky tests.
Technical approaches
The range of technical options available for handling flaky tests is quite broad (a testament to how ubiquitous flakies are, and how useful it is to address them). The most common approaches at scale are:
- Automatically identify and isolate flaky tests. Successful systems track test runs and their outputs, rerunning failing tests to get a pass/fail ratio that shows if they’re flaky. They automatically quarantine flaky tests (using a wide range of quarantine strategies) and may collect additional telemetry about them once quarantined.
- Assign ownership and report on progress. Advanced CI tools automatically apply clear heuristics and assign ownership of flaky tests (such as to the last engineer to modify the test or code owner for the product). Visible reports are important since they track ownership and progress addressing flakies.
- Remove opportunities for flaky tests to exist. For example, running tests in random order makes it difficult for tests to have interdependencies. Running each test in an isolated environment without shared storage or networking also helps. Hard limits on resource consumption (e.g., execution time, memory, and CPU) further reduce test complexity and help catch flaky tests earlier.
- Pre-process and batch change requests, using heuristics and ML to instrument each request for more efficient merging and quicker flake detection (for example, at Uber). This can identify flaky tests caused by concurrency problems or the staleness of a change request.
- Develop fine-grained control for product features like feature flag systems and server-side control over UX components. This gives you more chances to detect and address flakies early in the delivery process. If any problems make it past testing, the relevant feature flag can be turned off, and dynamic UX can gracefully support users until problems are addressed.
- Massively parallelize your test runs. Flaky tests impact build times by increasing the number of test runs per build. A massively parallelized test infrastructure, running batches of tests in parallel, can limit how flakies impact builds.
We built Test Engine for Delivery First organizations
Successful companies with a Delivery First mindset get the balance of confidence and speed right with their testing. To do this, they realize that a radical goal is the best way to drive change and they set ridiculously low targets for their build times. If under 10 minutes to build sounds impossible, know this: once you have the mandate to bring build times down, you don’t have to reinvent the wheel and implement the patterns above from scratch. These are solved problems (we know because we’ve solved them).
Buildkite’s Scale-Out Delivery Platform is designed for a Delivery First approach, and we understand what test infrastructure has to do to empower you to move fast and innovate. To that end, we’ve built Test Engine. It supports:
- Detection and quarantine of flaky tests: Test Engine integrates with CI and keeps track of test reliability over time (including data from both manual and automatic reruns). Any test that crosses a flakiness threshold is automatically isolated and quarantined.
- Effortless orchestration: Test Engine intelligently and automatically distributes tests across CI resources for optimal build times, and supports all major testing frameworks. Soon it will also be able to dynamically select and run only the tests that are relevant to each CR.
- Real-time insights and automation: Test Engine applies flaky test detection algorithms in real-time, integrates into analysis and reporting pipelines, and acts as a central, single source of truth for information for all test activities. The system will soon also support flexible automation for various features, such as the heuristics used for test quarantine.
- Ownership and accountability: Define test ownership and let Buildkite automatically assign flaky test ownership to the team most likely to be able to fix it. With Test Analytics, teams can set up individualized tracking and reporting to integrate CI responsibilities into their flows and processes. With the soon-to-be-released code coverage reporting integration, you’ll be able to detect over- and under-testing and optimize coverage to your specific needs.
To explore Test Engine for yourself and to see how it supports the adoption of a Delivery First approach, start building with a free 30-day trial. It takes less than a minute to sign up.