I'm a Software Engineer at Up, a digital bank headquartered in Melbourne. We’re the fastest growing and best loved digital bank in Australia, and that success has a lot to do with our ability to quickly release new and useful features to our end users.
One of our mottos is, “We’re in the business of shipping software updates often." From the start, we’ve always placed a lot of importance around being able to deploy code to production really efficiently — both server code, and our Android and iOS apps. We’ve been making around 5 deployments a day since the first day we had a production environment to deploy to.
Of course, we’ve faced some challenges shipping updates to our mobile applications. Native on-device testing (of both Android and iOS applications) is inherently quite complex and resource intensive. The tooling is challenging, and can be unreliable with nasty, unexpected edge cases. Despite these downsides, we’ve also found that this style of testing has been invaluable time and time again to ensure that we’re shipping the best possible product to our users.
Recently we've made some massive improvements to our Android build and testing speeds.
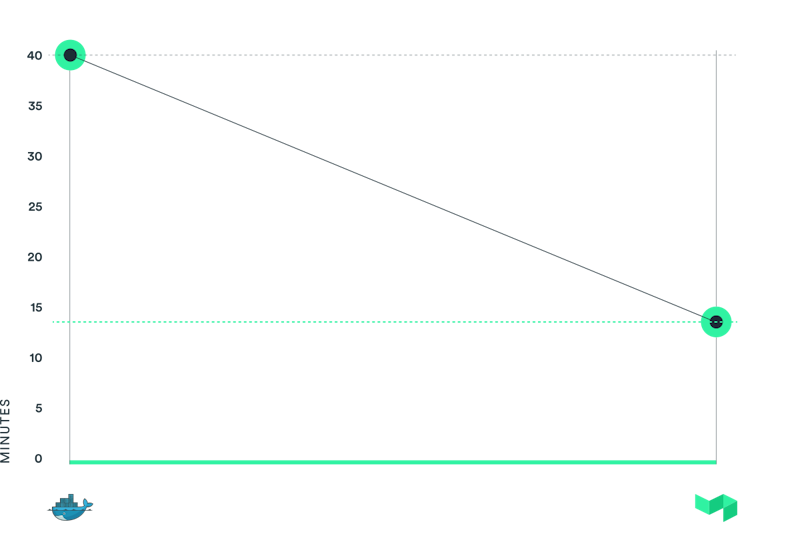
We've seen a massive 65% reduction in overall Test job times
We achieved this by removing Docker, better utilising GCP hardware and Buildkite parallelisation, I wanted to share these techniques with other teams building mobile applications.
Starting Out
Initially we ran Android tests and builds on a bunch of Mac minis and hardware we had lying around—we had some prior experience here, and this worked really well initially to get us off the ground.
As we grew the team and codebase, however, this approach threw up some tricky scalability issues. We quickly became constrained by needing to add and provision new hardware, manage them and ensure they were all working properly, not to mention the cost of powering, cooling them, and so on. Small divergences in machine configuration or spec would lead to hard to trace failures, which would burn valuable engineering time to track down, and the lack of ability to efficiently scale meant that test turnaround time was becoming increasingly frustrating.
At the same time we were having great success with managing the rest of our test suite. We were able to leverage Docker based testing across our custom multi-regional autoscaling pool of Buildkite agents running on Google Cloud Platform (GCP). This setup had proved to be secure, scalable, reliable and relatively cheap thanks to the ability to use preemptible instances—think the Elastic Stack but for GCP. Importantly it was also operationally simple for us to manage — changes were just a packer build and terraform apply away.
With this cloud-based infrastructure working so well for us we decided to lean into it and a year or so ago ported our entire Android testing stack (the SDK, emulator, everything) to Docker. We then shifted it off our own hardware and into GCP.
Initially this was a huge pressure relief for our testing scalability, and bought the team a bunch more time, though at the cost of efficiency and greater complexity, which eventually also started to result in flakey and time consuming testing, slowing down our ability to deliver features to customers.
The first issue we started encountering running Android under Docker is that simply putting the Android SDK into a Docker image—while great for packaging and encapsulation of that whole mess of tooling—resulted in a comically sized 11GB image that we then needed to have test runners fetch. Making changes became a nightmare because of the long turnaround time, and it’s very inefficient to send images this size over the network. Given the autoscaling nature of our CI infrastructure, this was a deal breaker; speed and efficiency is just too important when working with cold-caches.
Beyond that we found that even just having Docker in the mix when running a really resource intensive process like the Android Emulator was just quite unreliable. We encountered all manner of weird little edge cases and errors with the daemon, as well as pretty poor test throughput in general.
Back to the (kinda) Metal
So what could we do about the flakiness and poor performance? We had a few theories; removing Docker was at the top of the list, but beyond that we had some testing we wanted to do around how to best configure things to get the most out of the Android Emulator in a cloud environment...
Hypothesis 1: Docker is slowing us down
Not a particularly controversial one to start with! During initial work we immediately observed a modest (~6%) performance improvement and observable stability gain (fewer test retries) from simply moving the Android Emulator process out of Docker. This performance change was also evident in emulator boot time, which dropped from ~120s to 25s — not bad!
The Android Emulator relies heavily on being able to leverage the underlying system virtualisation—in our case KVM via GCP’s nested virtualisation support. It’s unclear if we were running into some sort of edge case here where the addition of Docker was in some way impairing KVM working in some way.
Additionally, all this was relatively easy to achieve by just building up a new machine image, creating a new Buildkite queue and then tweaking our build scripts a bit. We now build the Android APK up front and then fan it out to a pool of runners that are able to pull it down and test against it. By dropping Docker we were also able to eliminate a whole set of obscure work-arounds and retry logic that we had in place to deal with issues arising from using the old system.
While we lose a small amount of convenience when updating or tweaking Android system things without having Docker as a packaging mechanism, it’s more than worth it given these events are pretty rare, and we’ve got good tooling in place to support that anyway.
Hypothesis 2: Higher base CPU clock speed will make things better
Switching from N2 instances over to use compute optimised C2 instances, which have a higher base CPU clock speed yielded an immediate ~12% improvement in test time, and also resulted in significantly faster APK builds.
Given these instances are only very marginally more expensive than N2 instances when we’re running them as preemptible instances this was a really nice win.
Hypothesis 3: Adding a GPU will make things better
One of the other key things we wanted to test out was if the attachment of a GPU would result in faster and more efficient testing—it certainly has a big impact during local development! Thankfully GCP makes this possible via the ability to provision VMs with GPUs attached.

Up's Android Test Runner
Passing a GPU through to the Emulator made a significant difference in the responsiveness during testing (our app is pretty UI intensive). Gestures all work really nicely, there are far fewer instances where the UI slows down or gets janky, and most importantly when observing the Emulator the CPU is now freed up and isn’t being monopolised emulating the GPU. Even over VNC the performance is decent!
While this was all looking pretty promising, the improvement was less significant than I’d hoped for and was related to the fact that the emulator CPU now seemed to be the bottleneck.
Unfortunately GPUs in GCP can currently only be attached to older N1 instance types, which have a relatively low base clock speed compared to the newer N2 instances that we’d previously been using, and certainly slower than the C2 instances that we’d just tested.
Ideally we’d adopt both C2 instances and pair them with a GPU for optimal performance, however given that’s currently impossible we decided to set aside using GPUs on our agent instances. Hopefully Google will allow using GPUs with a variety of instance types in the future.
Outcomes
Overall our Android testing infrastructure is significantly more stable and scalable than before, and is also easier to work on and maintain thanks to Buildkite’s unique agent model.
As a result of removing Docker and adopting C2 instance types, along with optimising our pipeline, and scaling out our the way we parallelise work, we’ve managed to reduce the total time to execute Android steps by approximately one third, as well as significantly reduce the delay before we start executing those tests, meaning much faster feedback cycles.
Critically we’re now able to parallelise CI work to an almost arbitrary degree based on our appetite for CI speed and cost.
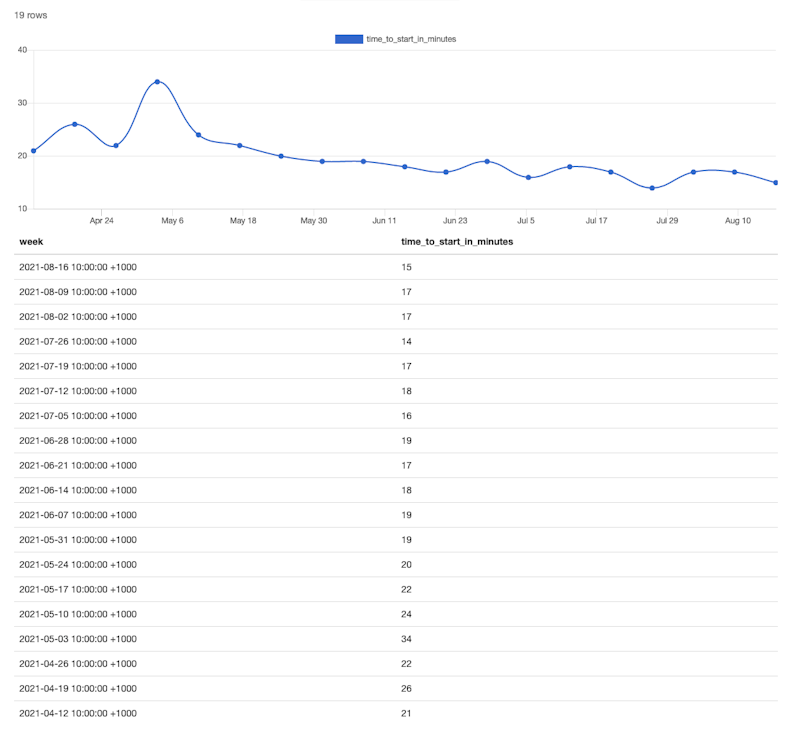
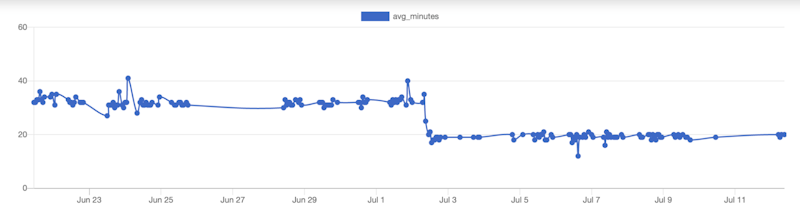
Average time to start Android tests (in minutes)
We’ve seen a massive reduction in time to start testing. Before the removal of Docker from Android we averaged 34 minutes before Android testing could even start running in our pipeline. That time includes seeding data, building the Android app, distributing it, and spinning up integration environments in GCP. With the adoption of our changes we’re steadily trending downward, and expect the time to keep lowering as we tweak things going forward.
Average Android test job times
We’ve also managed to drastically reduce average duration for Android test jobs, the change when we cut over to using our new pipeline is pretty pronounced, with approximately a ~14 minute reduction. Significantly this doesn’t take into account that previously we also had a much higher failure and retry rate, so the actual time to completion across all parallel steps as a part of a build could be multiplied out from this value.
Takeaways
One of the joys of engineering at Up is that taking the time to sort out small inefficiencies before they take root in ‘business’, is valued and supported. We are very proud of the testing delivery pipeline we’ve been able to create. It’s a critical asset for our business and underpins how we want product and engineering to be able to ship to customers.
There’s not always a straightforward answer to getting things fast and keeping them that way, but it’s definitely worth teasing out and testing possibilities.
If you’re seeing similar inefficiencies to those above, I hope that our experience can help you cut back your testing time. And if you find more possible ways to do it, or have questions, you can find me at @plasticine on Twitter. If you're interested in working on problems like this, we'd love to talk to you. Hit us up at careers@up.com.au