Dev teams need automated tests to build and maintain apps as smoothly as possible. For every new piece of functionality added or refactoring done, test coverage gives peace of mind that something new won't break.
While this is excellent for improving developer productivity, all automated tests must be deterministic. In other words, they should keep producing the same results if the code hasn’t changed. Flaky tests go against this very essential property, neutralizing the benefits of CI/CD and reducing the developers’ trust in their test suite.
Instead of rerunning or disabling flaky tests, you should prioritize fixing/replacing them.
Here’s a step-by-step guide to help you achieve this.
Step 1: Have a “fix it now“ mentality with flaky tests
The best time to fix a flaky test is the very moment you identify it.
The related history of the test, whether it’s new or had a recent commit change its stability, will be fresh in the developers’ memory, so they can act quickly. But if you delay fixing the flaky test, you’ll always have them standing in the way and growing your technical debt. Not only will it slow down development by affecting both the CI pipeline and the test suite, but it’ll also waste time and delay software delivery (if you choose to rerun it).
That said, there are times when it’s not possible to fix a flaky test right away. In these cases, you should document it, create a ticket, and commit to fixing it as soon as possible.
Step 2: Locate the flaky tests in your test suite
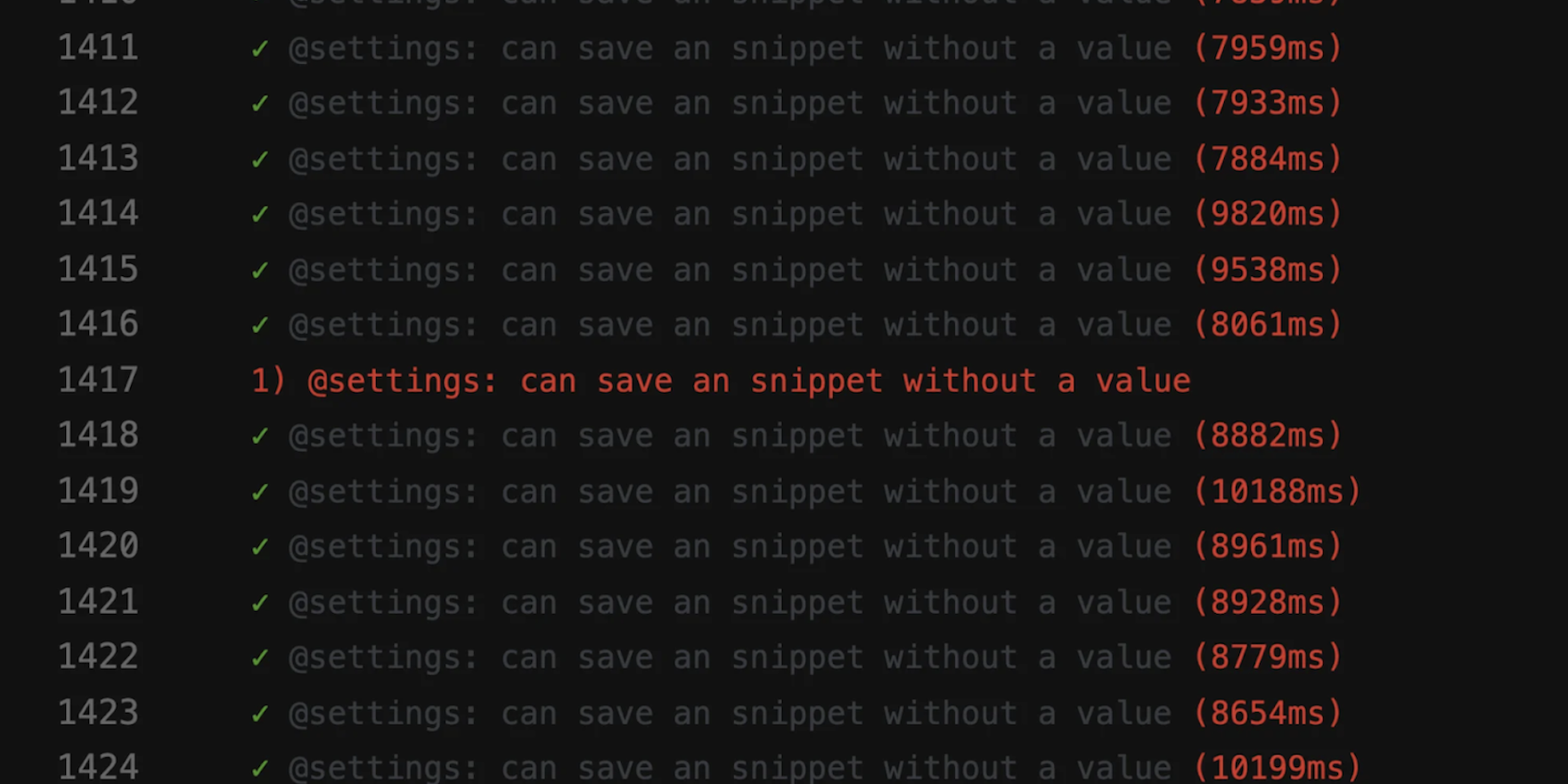
A flaky test is statistical. You have to observe it over a specific time period to understand its behavior. The more it runs, the more likely a pattern will emerge, and the easier it’ll be to determine a suitable solution.
Next, save the debugging information. From event logs to profiler outputs to memory maps, flaky tests can stem from anywhere. Save every little information you can to effectively detect the root cause of the flakiness. You can also add debugging messages or any other instrumentation to make sense of the logs.
SSH debugging is another option for a quick diagnosis. You can reproduce the conditions that cause the test to fail and try new solutions to fix it. Remember, the changes will be lost when the session ends, so you’ll have to reapply any modifications as a normal commit in your repository.
UI tests are definitely the most challenging class of flaky errors. End-to-end and acceptance tests depend on the graphical elements that aren’t represented in logs, so you’ll have to configure your test framework to dump HTML or screenshots whenever a test fails.
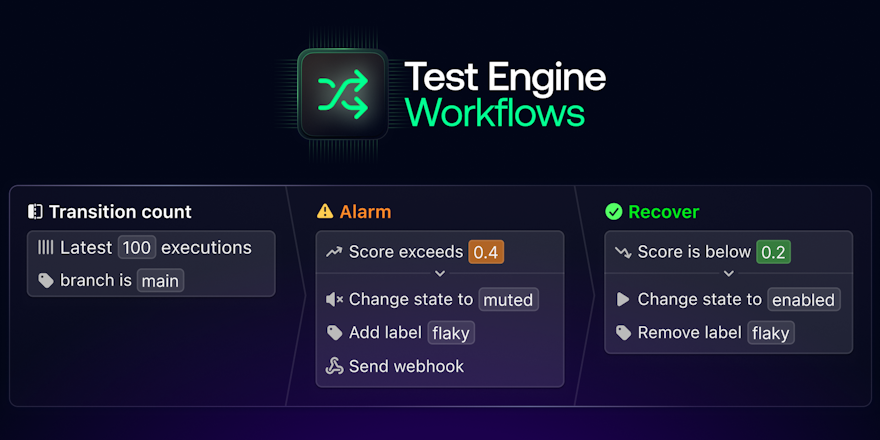
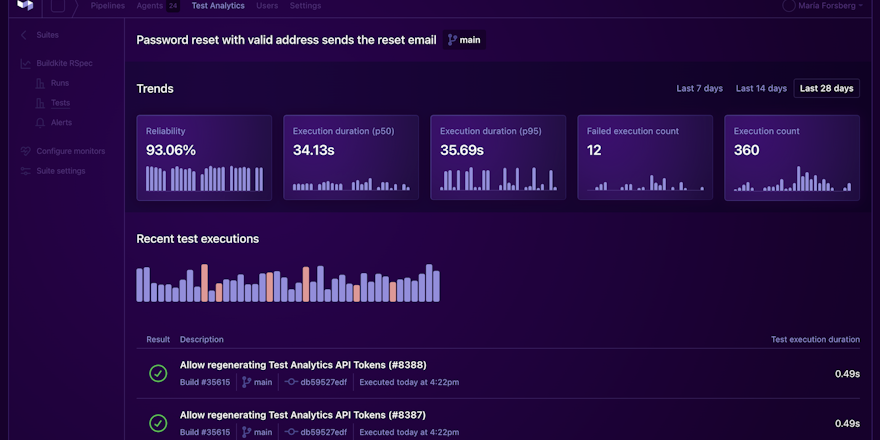
The easiest way to find flaky tests in your suite is using a tool like Buildkite Test Analytics. Test Analytics lets you perform automated tracing across your test suite to quickly identify which tests are the most disruptive for your team and get a head start on fixing them. There’s also speed and reliability monitoring that highlights a specific pattern — for example, a test only fails between 1 PM and 5 PM — helping you identify flaky tests as soon as they occur.
Step 3: Document all info related to flaky tests
Once you know where your flaky tests are, document each one of them into your ticketing system. Keep adding any more information you get concerning the cause of the test’s flakiness. If you think you can fix the tests right away, just do it!
The good thing about having a ticketing system is it encourages devs to share ideas to fix flakiness faster. Also, if you have too many open tickets, treat it as a sign to set aside time and improve the test suite’s quality.
Step 4: Identify the potential cause of the flaky test and fix it
When the cause of failure is obvious, you can quickly fix and close the test. But when it’s not immediately clear why a test is failing, you’ll have to deeply analyze all available data.
Asynchronous waits
When writing tests, devs commonly rely on specific data. If the tests run before the data loads, they become unreliable. This is a common issue in languages that extensively use asynchronous APIs like JavaScript, Go, and C#.
Suppose you perform an integration test that fetches data from an external API. If you find the application code makes an external API call asynchronously without explicitly waiting until the data is ready, the test will be flaky. This is because sometimes data will be ready when needed for testing; other times, it won’t.
Testing success or failure depends on factors like the speed of the machine the code is running on and the quality of the network connection.
In such cases, you can either opt for polling (performing a series of repeated checks to see if expectations have been satisfied) or callback (allowing the code to signal back to the test when to start executing again).
Concurrency
When devs make incorrect assumptions about the order of operations that different threads perform, it leads to flaky tests. This can be due to data releases, deadlocks, leaky implementations, or implementations with side effects.
Concurrency issues typically stem from using shared resources. To avoid this problem, consider replacing the shared resource with a mocked component.
Non-deterministic code
If your code relies too much on unpredictable inputs (think: random values, dates, remote services), it’s likely to produce non-deterministic tests. The good news is you can prevent this by exerting a tight degree of control over your test environment.
Inject known data using mocks, fakes, and stubs in place of otherwise uncertain inputs. This will give you greater control over random inputs in your tests.
Environmental differences
Another common cause of flakiness is when there is a difference between your local development machine and CI.
Variances in operating systems (OS), environmental variables, libraries, number of CPUs, or network speed can result in flaky tests. Of course, having identical systems isn’t practical. But you should still be stringent about library versions and consistent in the build process to avoid flakiness, especially considering even minor version changes can introduce unexpected behavior or bugs.
Aim to keep the environment as equal as possible during the entire CI process to reduce the chance of creating flaky tests. Containers, for example, are great for controlling what goes into the application environment and isolating the code from OS-level influence.
Improper assumptions
When writing tests, devs often make certain assumptions, such as expecting the database to be already loaded in the database. But there’s a possibility the assumptions may be incorrect.
Your best bet here is to make tests completely self-contained. This involves preparing the conditions and setting up the scenario within the test.
Alternatively, you can check your assumptions before executing them. JUnit having an assumption utility class where it aborts a test without failing is an excellent example of this.
Order dependency
If you execute your tests in a different order than planned, you’re bound to encounter flakiness. You may think the best way to solve this problem is to conduct tests consistently in the same order, but it really isn't.
Conducting tests in the same order means you‘ve accepted your tests are brittle and their proper execution depends solely on the built environment. So, it’s a poor solution.
The root cause of the problem is the dependency of these tests on shared mutable data. When the data isn’t mutated in a predefined order, the tests fail. You can resolve this issue by breaking dependency on shared data. This will enable each test to prepare the environment for its execution and clean it after it’s done.
If you find the root cause stems from other shared data (for example, files on a disc, global variables), develop a custom solution to clean up the environment and prepare it before every test.
Step 5: Fix the flaky tests
At this stage, you have all the data about the flaky tests — where it is, what’s the cause behind it, and the remedial measures you should take to resolve them. The next step is to start fixing them.
After fixing a group of tests, merge the branch back into the mainline to pass the benefits to your team. If the flaky test still fails, delete and rewrite it from scratch to replace the test altogether.
Solving the flaky test problem with Buildkite’s Test Analytics
DevOps teams spend a considerable amount of time rerunning flaky tests on the assumption the code being tested will eventually pass because the test is poorly constructed. For instance, we rerun more than 800 million seconds (that’s equal to 25 years) of tests every month—largely due in part to flaky tests—every month.
We built Test Analytics to improve Buildkite's ability to identify flaky tests and save teams time. Alongside integrating the tool with our Pipelines product, you can also apply it to tests residing in other CI tools like GitHub Actions, Jenkins, and CircleCI.
Here are a few other advantages of using Test Analytics:
- It comes with a dashboard that identifies the slowest and least reliable tests, making it easier for devs to prioritize test remediation efforts. The dashboard also includes historical views and graph trends to provide further insights into recurring flakiness issues.
- You can define whether a test is slow or unreliable, with the tool generating custom alerts identifying problems as soon as they occur. Integration with commonly used testing frameworks further helps drive dev productivity.
- Besides speeding up builds and reducing interruptions, Test Analytics also defines and tracks your speed and reliability targets. Every test suite is different, so spotting problems as early as possible will help to keep CI compute costs under control by configuring alerts for speed and reliability.
- Diagnosing problems also becomes easier than ever, thanks to its deep tracing and instrumentation capabilities that let you see why tests are slow or are behaving differently between executions.
Ready to fix/replace flaky tests and improve dev productivity? Schedule a Test Analytics demo now to see the tool live in action. Or try it free.