On the 22nd of August 2016 at 17:21 UTC, Buildkite suffered a severe unplanned outage. During this period Buildkite was still able to run builds and update GitHub/Bitbucket Pull Request statuses, but no one was able to login, view build logs or read documentation. This is a full account of what happened, what changes we’ve made and lessons we learned.
What a morning…
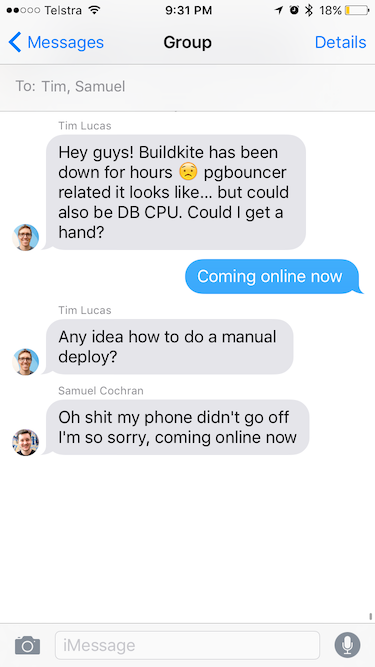
The Buildkite team are currently based out of Melbourne, Australia — which meant we were all asleep when we first went offline (3:21 AM AEST). Usually if this happens our primary on-call person would get a phone call from PagerDuty letting them know that Buildkite is having problems, but due to mis-configured settings on PagerDuty and our phones being on “silent”, that didn’t happen.
We woke up at 21:00 UTC almost 4 hours after we went offline to see our phones full of emails, tweets and Slack messages letting us know Buildkite was down. Many expletives were yelled as we all raced out of bed, opened laptops, and started figuring out what was going on.
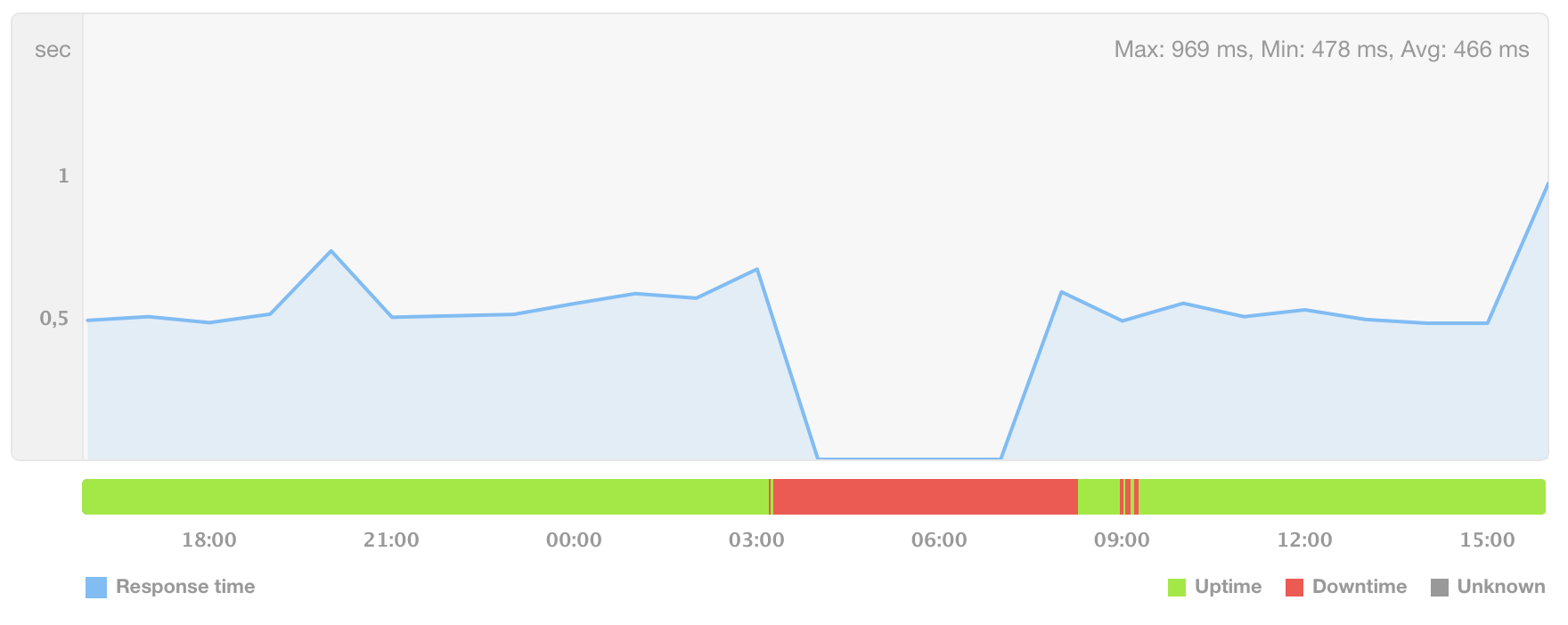
It took us a while to figure out what was going on, and at 22:28 UTC we made some temporary fixes to get buildkite.com back online. Although we were able to start servicing web requests, our response times were really bad and some requests were just getting dropped.
We finally recovered at 23:10 UTC and spent the rest of the day working on making sure this doesn’t happen again.
Trying to reduce our AWS bill
About a year ago we were accepted into the AWS Activate program and awarded a bunch of credits to spend on AWS infrastructure. Since then we’ve been growing fast and used the age old method of “just buy more hardware” to solve our scaling problems. This was a cheap solution in terms of time and allowed us to get on with building out the rest of the product.
About 2 weeks ago we discovered that those credits were about to run out, and we needed to start aggressively working on reducing our AWS bill. We paused product development and spent some time coming up with a plan to reduce the cost of the next bill.
The main culprit was our m4.10xlarge Multi-AZ RDS PostgreSQL database. We looked at some graphs and decided to downgrade to a more affordable r3.2xlarge Multi-AZ RDS PostgreSQL instance.
Since we felt pressure to get these changes out sooner rather than later, we didn’t do our due diligence to figure out if this new database would perform under heavy load.
Lesson #1: Keep an eye on AWS credits so you’re not rushed to make significant infrastructure changes in a short period of time. AWS Billing Reports show $0 bills while you’re spending credits, so it’s really hard to know what your actual costs are.
Database performance issues
We scheduled a maintenance window on the weekend to downgrade the database. The downgrade was successful and everything was looking great. The performance of the new database looked fine and we were happy with the results.
Our largest customers are in US timezones, so we wouldn’t really have known how the database was going to hold up under heavy load until Monday morning in the US (Monday night for us). We monitored it into our evening and what we thought was the beginning of the US peak period and everything seemed to be tracking okay, so we went to bed.
Since the new database didn’t have as much memory as the old one, we also moved to a centralised pgbouncer to pool connections across all of our servers in hopes to reduce the per-connection memory overhead.
At around 16:00 UTC the database started struggling. It couldn’t keep up and its CPU started maxing out. These performance problems started a cascade of other issues.
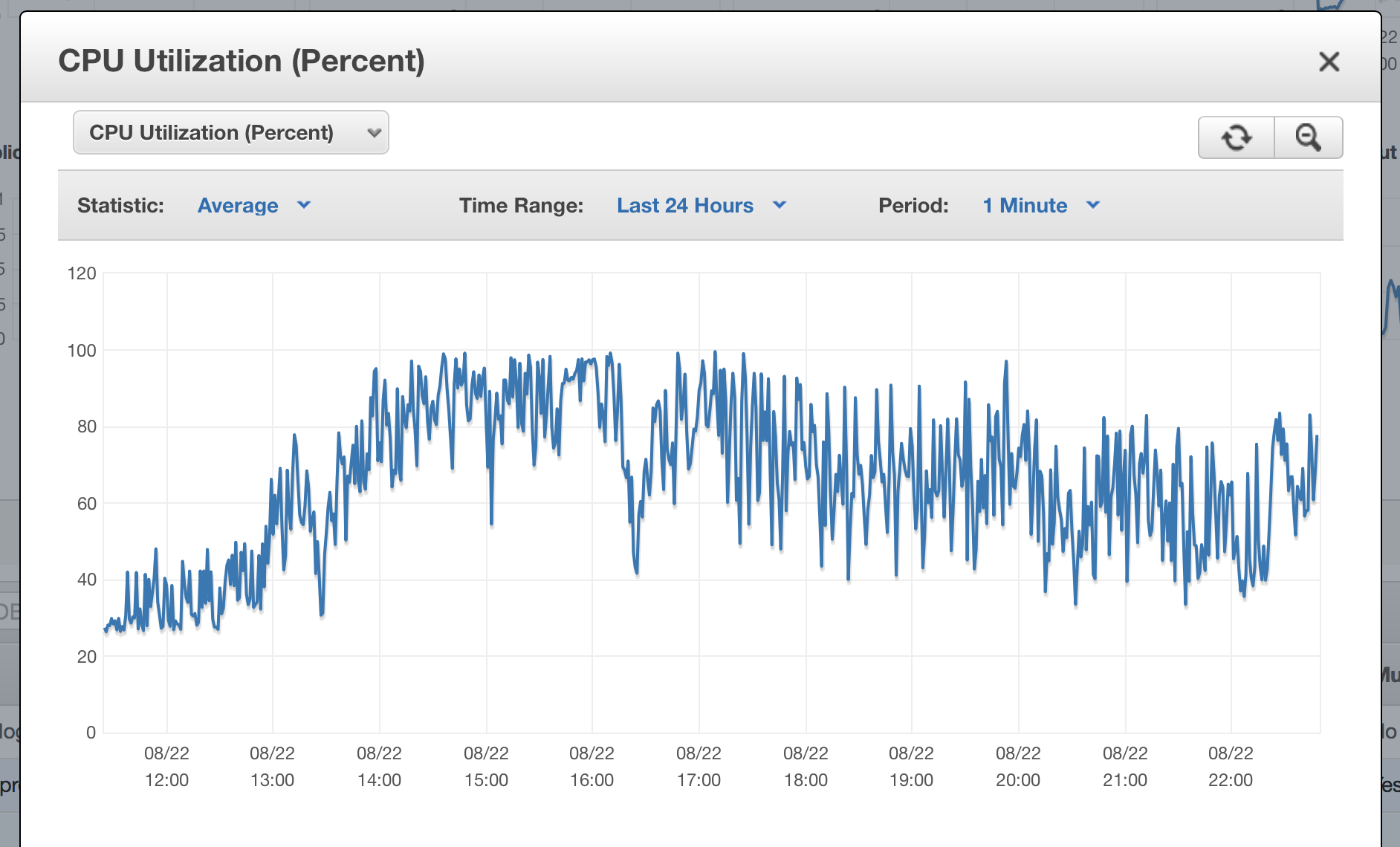
Lesson #2: Do load testing after significant infrastructure changes. Due to the tight time constraints before the next AWS bill, we didn’t load test the new database or the centralized pgbouncer setup. We’ve already started planning how this could work and ways we can do it without impacting others using the system.
Failing health checks
Buildkite has 3 major Elastic Load Balancers and Auto Scaling Groups. One handles all requests to the Buildkite Dashboard, one handles all requests to our REST API, and the other handles all Agent API traffic. This separation works really well because we can scale each one individually since they all have very different traffic profiles.
The ELBs perform health checks by making HTTP requests to our main application every 30 seconds. If those checks return HTTP 500 errors in succession, it automatically removes those servers from the ELB and marks them as “OutOfService”.
Our health check endpoints hit our 2 SQL databases along with our Redis and Memcache servers to ensure the application is running smoothly. It essentially looks like this:
class HealthCheckController < ActionController::Base
class UnhealthyError < RuntimeError; end
def index
[ ActiveRecord::Base, Job::Log::Chunk::Shard::Two ].each do |ar|
ar.connection.select_value("SELECT 1") == "1" or
raise UnhealthyError, "Database ping failed"
end
$redis.ping == "PONG" or
raise UnhealthyError, "Redis ping failed"
Rails.cache.dalli.version.values.all?(&:present?) or
raise UnhealthyError, "Memcached ping failed"
render plain: "OK"
end
endWhen the database performance problems started, the health check endpoints started returning HTTP 500 errors that it couldn’t connect to the database. The failed health check threshold is much lower for the ELB servicing dashboard requests, so it automatically started removing servers. The ELBs for the Agent API and the REST API were having some issues, but the servers remained in the ELB.
Normally when servers are removed from the ELB due to health check failures, they’re replaced with new ones. When the new ones have finished launching, the ELB starts performing health checks. Due to an error in how we bootstrapped these new servers and some of our recent infrastructure changes, the health checks failed which meant no new servers could come online to replace the ones that were removed.
Over the course of a few hours, this caused a cycle of new servers to launch and terminate instantly due to failing health checks.
Lesson #3: Re-think what a health check should actually do. Our first iteration checked that it could connect to all dependent servers. We didn’t consider what happens if all servers in an ELB failed health checks. We need to figure out the trade offs here: would we prefer all servers to get dropped out of an ELB? Or would we prefer to just throw HTTP 500 errors if it can’t connect to our database. We’ve switched it now to just return “OK” if it can hit the app. We don’t check database connectivity in this request anymore. We’re also considering adding another health check endpoint that Pingdom can hit which makes sure the application can connect to the database and any dependent services.
Replacement servers not going healthy
New servers that are launched by the Auto Scaling Group are based off an AMI that we only build when we make changes to server configurations. This AMI has a version of the codebase baked into it at the time it was built — so when they come online they need to figure out what the latest version of the codebase is and deploy that to itself.
Our first version of “how do we find out what Git revision is deployed to production” was to cURL a special endpoint that we created that returned the current revision: https://buildkite.com/_secret/version
This works really well if buildkite.com is online… We always had the intention of improving this but other stuff just got in the way and it dropped off our radar.
Since it couldn’t grab the latest version, it just rolled with what ever version of the codebase that was baked into the AMI. The health check in this version referenced an old database Job::Log::Chunk::Shard::One which has since been decommissioned. This meant all health checks failed against new servers and they never got added to the ELB.
Lesson #4: Don’t do this. We’ve now switched to storing the latest deployed revision as file on S3 and we reference that when newly launched servers need to self-deploy.
Our “on-call” setup failed
While all of this was happening, the Buildkite team were fast asleep.
We have various services watching Buildkite all the time: New Relic, Pingdom, Datadog, Calibre and CloudWatch. If any of them start seeing issues on Buildkite, they create a PagerDuty alert which phone calls the developer who’s been designated “on-call”. This week it was my turn.
I still haven’t figured out how this happened, but the “Immediately phone me” rule was somehow dropped as a “Notification” from my settings. I have “Do Not Disturb” turned on my phone in the evenings, but I allow PagerDuty to call me if anything comes up. Since I didn’t get a phone call (just push notifications which don’t make any sound) I didn’t get woken up.
We have escalation policies setup so if someone doesn’t acknowledge a PagerDuty alert it goes to someone else. The other team members had their phones on “silent” since they weren’t designated as the primary “on-call”, so they didn’t get woken up either.
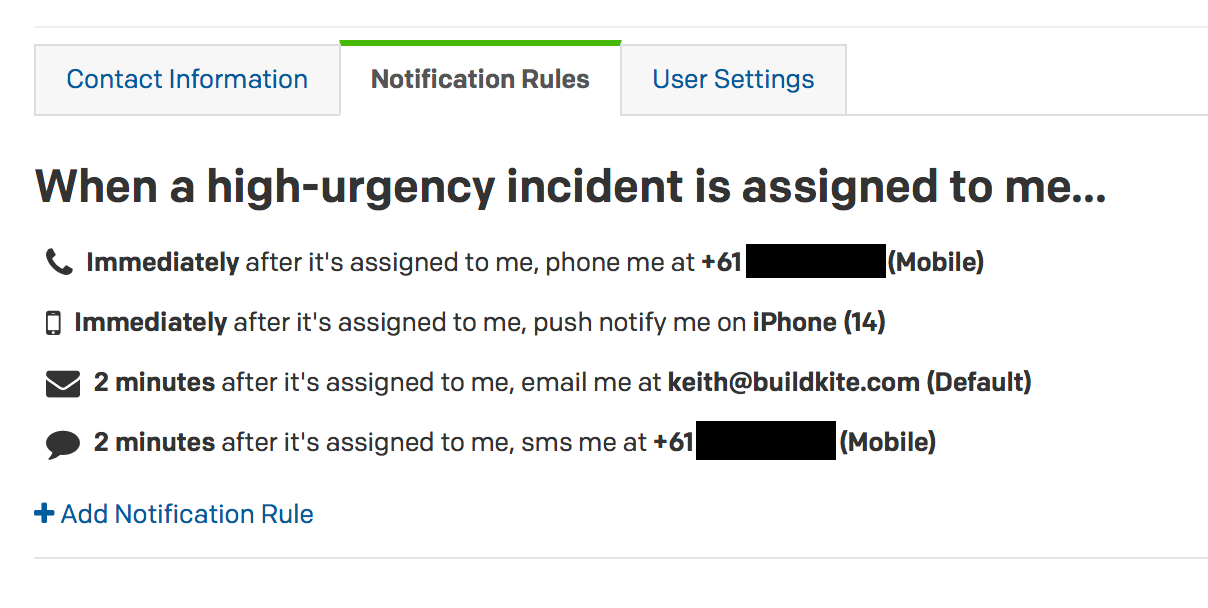
Lesson #5: Ensure all on-call team members have the correct PagerDuty and iPhone settings before going on call. We’ve all done manual tests to ensure calls are getting through. We’d like to investigate whether or not we can trigger company-wide tests to make sure everyone’s setup is correct on a regular basis. Another idea is to have PagerDuty call team members when they go “on-call” — or have a requirement that all Notification Rules contain a “Immediately phone” rule. We haven’t looked into whether or not PagerDuty supports this out of the box, but we’ll be reaching out to them to see what we can do.
AWS issues prevented us from fixing anything
Once we were all online and had finished identifying what the problems were, we decided the first thing we wanted to do was upgrade the database.
We logged into the AWS Console and tried upgrading the database, but due to IAM issues AWS was experiencing, the interface wouldn’t let us make the changes. We checked the AWS Status Page and noticed they were having problems, so we decided to skip this step for now and go onto the next thing.
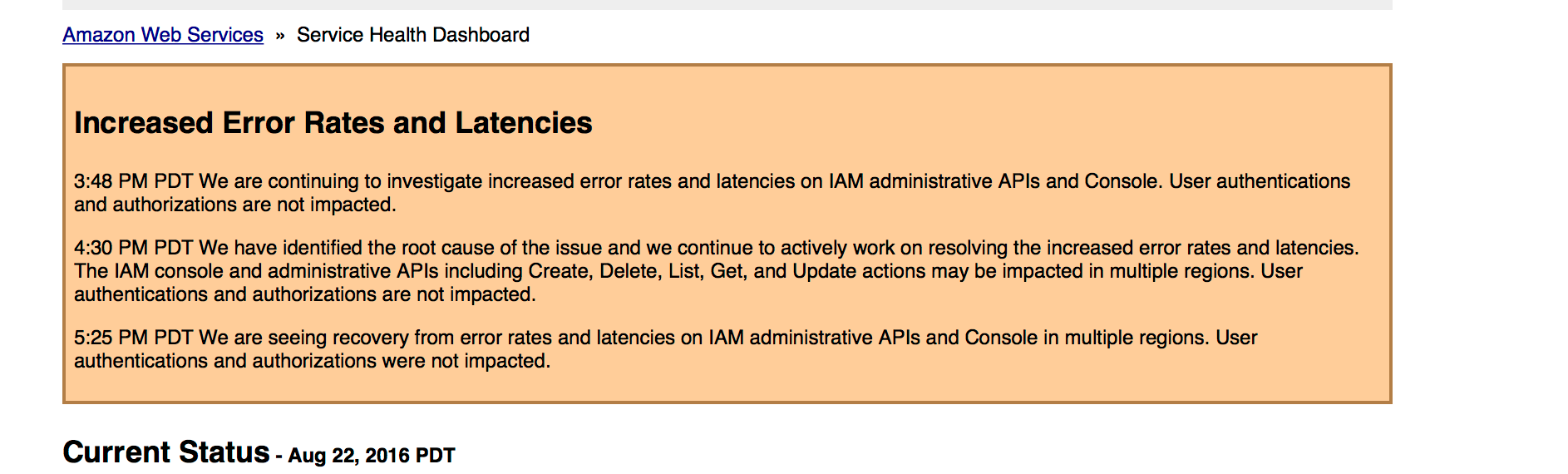
We needed to push out a new AMI to our servers that didn’t reference https://buildkite.com/_secret/version. We made the necessary changes, built the AMI and decided to test it out before deploying it to the rest of our infrastructure. When we tried to launch it, we discovered the IAM role selector wasn’t working either. We kept getting “Internal server error” in the AWS Console — which we guess to be IAM related.
At this point we stole some servers from the Agent API and added them to the ELB that services requests for the dashboard. This allowed us to bring buildkite.com back online — although requests were slow due to the database still being under heavy load.
Once the IAM issues had subsided we tried launching new EC2 servers, but we got hit by another AWS issue: EC2 request limits. Because servers had kept coming up, failing health checks, and going down again, we had reached out EC2 request limit. Our only option here was to wait it out.
After some time we were eventually able to upgrade the database to an instance type that could handle the load and roll out new servers that fixed self deploys. We had to use the aws-cli to do these last steps since the AWS Console was still having issues.
Along with upgrading the database, we also took this opportunity to remove the centralized pgbouncer server. We previously used to have pgbouncer installed on each host and pool from there. Since we knew the previous setup had worked well, we reverted back to that until we had capacity to investigate if the new pgbouncer setup was working.
Lesson #6: When you see high churn issues in AWS make sure to stop your health check and autoscaling rules so that you don’t run into future EC2 request limits. When we hit ours we changed the Auto Scaling Groups to EC2 health checks and locked in desired counts. As part of writing this postmortem, we discovered you can “Suspend and Resume Auto Scaling Processes” directly from within AWS — which would have been very useful if we’d had known about it: http://docs.aws.amazon.com/autoscaling/latest/userguide/as-suspend-resume-processes.html
Moving forward
Tim, Sam and I would like to personally apologise for the downtime. We know exactly what it’s like when services you rely upon have technical issues (AWS had problems when we were trying to fix ours). It’s incredibly frustrating and at times infuriating. We don’t want to be that sort of company and we don’t want our customers and friends to feel like that.
We’d also like to personally thank you all for your understanding during the downtime. It’s was very heart warming and encouraging to see such lovely tweets while we were working to get everything back online.
We can’t promise that we won’t go down again, but we can promise that we won’t make the same mistakes twice. Not only are we stronger technically, we’re a stronger team now because of it.
If you have any questions or would like to know more about what happened, feel free to email me directly keith@buildkite.com
❤ Keith, Tim and Sam