You write your test cases, run them in your environment in random order, and see all of them pass. But when you push your code later and have your CI server run the tests again, one of them fails for no apparent reason.
You run it again, and it fails again. But suddenly, it passes despite you not making any changes to the code or the test itself.
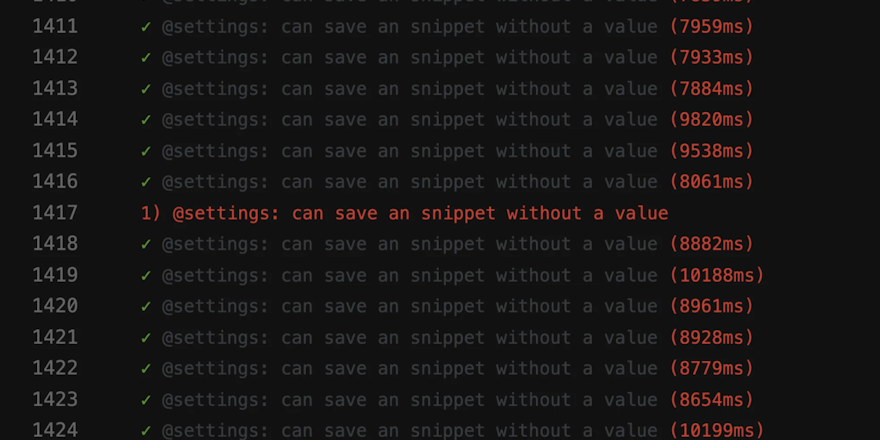
That’s a flaky test in your hand — and they sometimes pass and at times fail with no obvious reason. And yes, they’re just as frustrating as they sound.
There are many problems with flaky tests. They slacken development and progress, hide crucial design problems, and can turn out to be very expensive if not handled faster. They also significantly hinder the efficiency of CI: 47% of failed jobs succeeded in the second round when manually restarted.
What is a flaky test?
A flaky test is an analysis of web app code that returns both passes and failures each time you run the same analysis; it doesn’t produce the same result.
Unreliable test results stem from several factors like inconsistencies in the build environment, timing and time zone issues, failing to refresh data between test runs, and increased dependencies on the test execution order.
Regardless of the reason, flaky tests slow down your CI/CD pipeline and reduce your team‘s confidence in testing processes. There’s a lot of uncertainty and second-guessing. You’re unsure whether a successful test run means your code is free of bugs or whether you should spend more time trying to reproduce and fix an issue when a test fails.
Examples of flaky tests
Typically, you can categorize flaky tests into the following two heads:
- Order-dependent flaky tests: These tests may fail depending on the order of the testing. Use scripts/rspec_bisect_flaky to get the minimal test combination to reproduce the failure. Under Knapsack node specs: in the job output log, search for the list of specs you ran before the flaky test. Save the list and run the following: copy paste
In case of an order-dependency issue, the script above will print the minimal reproduction.
- Time-dependent flaky tests: These tests fail depending on the date of analysis so the computation will always be dependent on the current date. One of the most effective ways to fix these issues is to sandbox the execution of the tests to control the current date.
Several devs have publicly shared stories when they stumbled onto a couple of flaky test issues. Product developer Ramona Schwering shared her testing nightmare with Smashing Magazine, which does a brilliant job at highlighting the unpredictability of flaky tests.
For a UI test, Schwering and her team built a custom-styled combo box that let users search for a product and select one or more results. The testing was going fine for a few days, but then suddenly the test for searching and selecting a product in the combo box failed in one of the builds in their CI system.
A flaky test like this blocks the continuous deployment pipeline, slowing down feature delivery. These tests are also expensive to repair, requiring devs to put in several hours and even days trying to debug. The fact that the testing isn’t deterministic anymore means you cannot rely on the testing, too.
Flaky tests waste time and resources
The more variables you introduce within a test suite, the greater the likelihood of flaky tests because more variables mean more risk factors. End-to-end tests and integration at scale also result in a substantial level of flaky test results with the more complex contributing variables within a test suite.
But why are flaky tests so undesirable?
Aside from the frustration they cause, flaky tests drain your resources. They require developers to analyze and retest their codes, which leads to a significant wastage of time and costly interruptions.
Also, tribal knowledge is a vulnerability within test suites, especially due to the lack of ownership of historic knowledge of past test results. Many organizations today don’t have an updated, accessible database of this information, which causes the knowledge to become siloed by a team or individuals.
Flaky tests also breed code mistrust and general test outcome wariness that causes the engineering team to not trust test results. The whole point of testing is to get reliable results, and if you can’t trust them, why waste time creating them?
More importantly, if tests fail with false negative results every time, devs lose trust in the test suite. When they ultimately find a real bug using this test, they will think there isn’t one simply because they are already used to seeing the tests fail, even when there is no issue in the app at all.
Ways to deal with flaky tests
It’s important to take any error in the build seriously. Simply assuming a flaky test isn’t a real bug and therefore doesn’t need to be taken care of or even debugged is wrong.
Here’s a list of measures to effectively deal with flaky tests:
- Identify the cause of failure and fix it. While this is impractical on the large scale, identifying the cause of flaky tests and removing it should always be your first option. This is particularly important when the test is covering a critical user path.
- Rerun failed tests to determine the flakiness. If you find the failed test passes after you rerun it, move on. This approach will save you time at the moment, but it isn’t feasible in the long run. It can make you comfortable with the idea of not addressing the underlying issue and therefore make your test suite become less reliable over time. That said, there are certain situations, such as timing issues or temporary issues with the test environment, that nearly always call for a rerun. When rerunning filters, specify how many times consecutively this option can be used for one test and quarantine tests you feel are particularly flaky.
- Group flaky tests into a separate test run. Once you create a group of all your flaky tests, your team will immediately have more confidence in the rest of your test suite. It also makes it easier to discover other bugs if the test fails on a step other than the one you identified as flaky. Review the results of each test run in this separate group, but don’t make it a gating criterion to hold a release.
- Temporarily disable the test or remove it from the test run group. This is a good option if release speed is a greater priority than dealing with inconsistencies the test might uncover. Be sure to make a plan to fix the test in the future and hold your engineering team accountable for it.
- Delete the test. If the test didn’t identify any critical bugs or cover an important user path, think about whether you need the test in the first place. If not, consider deleting it.
Why Buildkite recommends fixing/replacing flaky tests
At Buildkite, we recommend fixing/replacing flaky tests to avoid costly interruptions to the main branch builds. The fact this will also improve your test suite’s reliability rate and identify (and fix) where your biggest problems are is another significant advantage.
Replacing the flaky test is another alternative, where you delete the test and write it from scratch, preferably by a developer who didn’t see the flaky one.
If you cannot develop stable tests for some part of the code, it means either something is wrong with the test and/or the testing approach or something is wrong with the code being tested. So, if you’re certain the tests are fine, it’ll serve you well to take a deep look at the code.
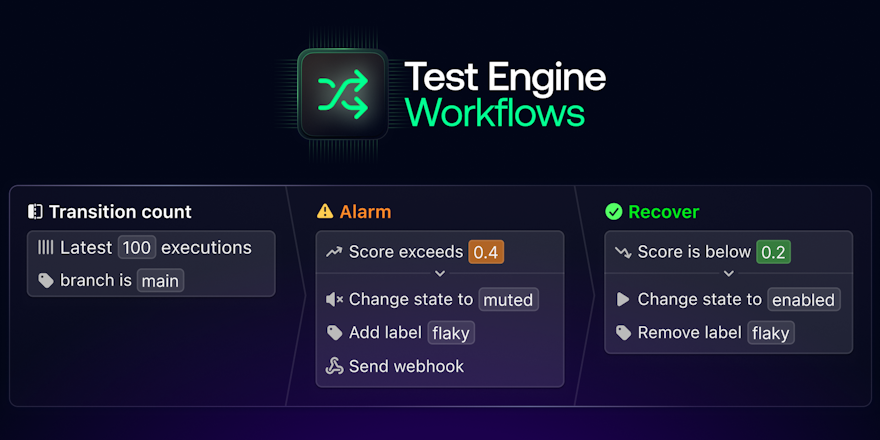
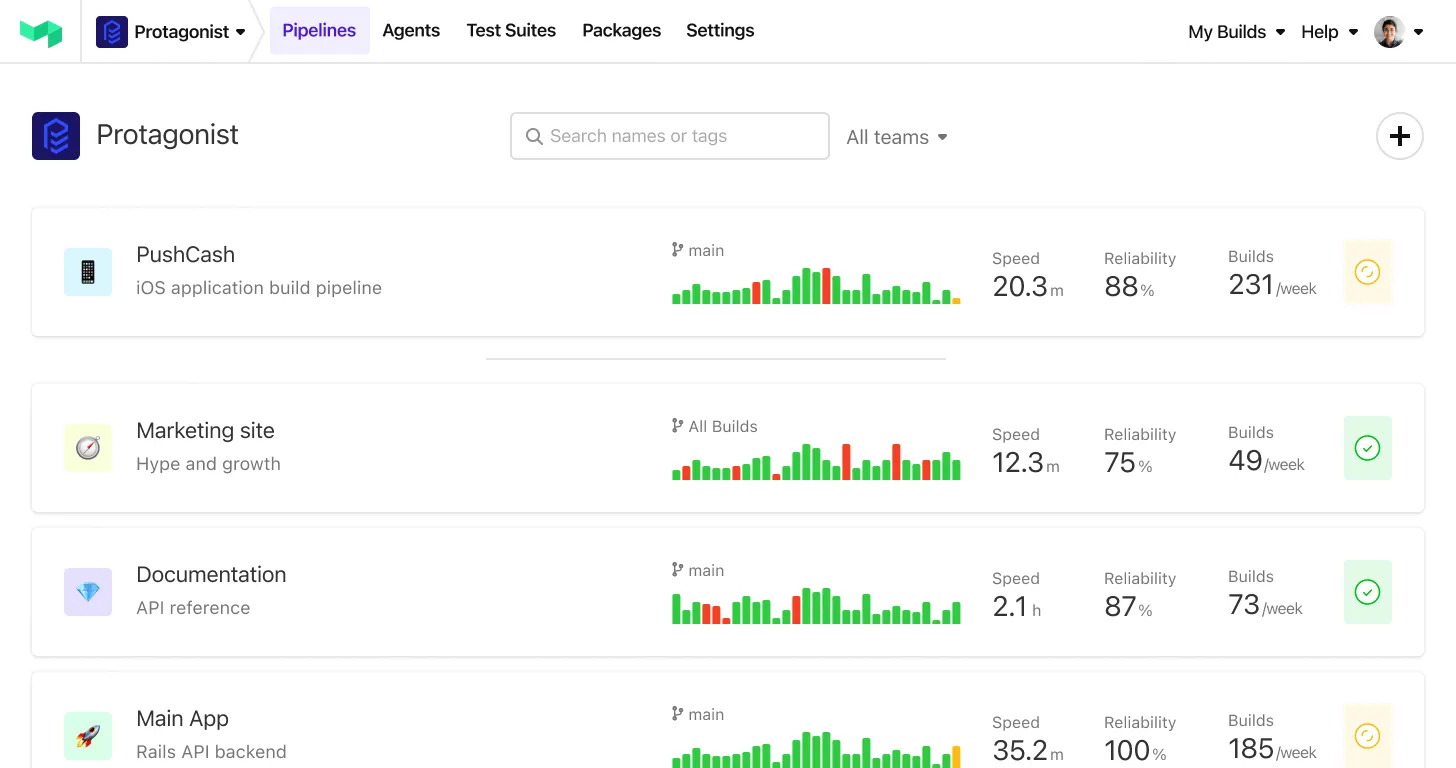
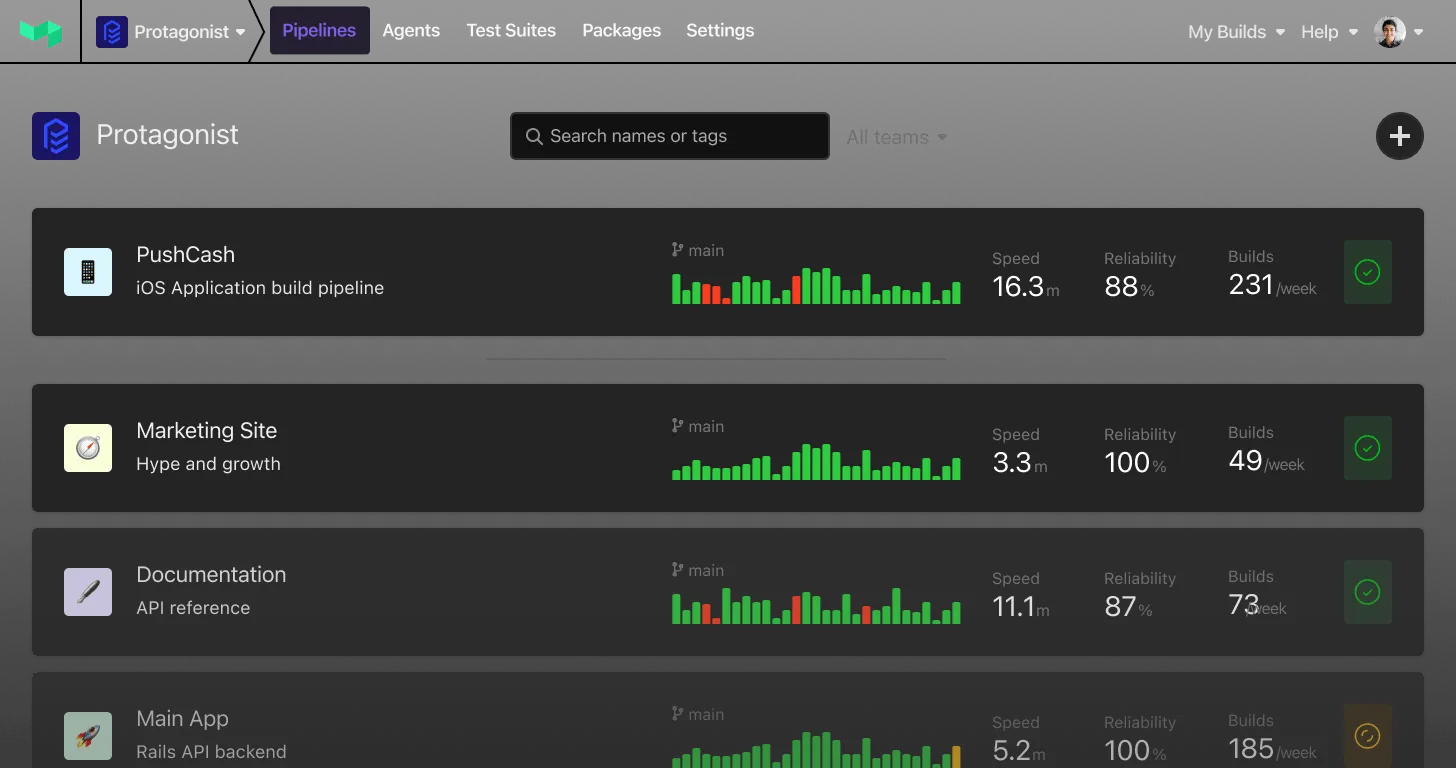
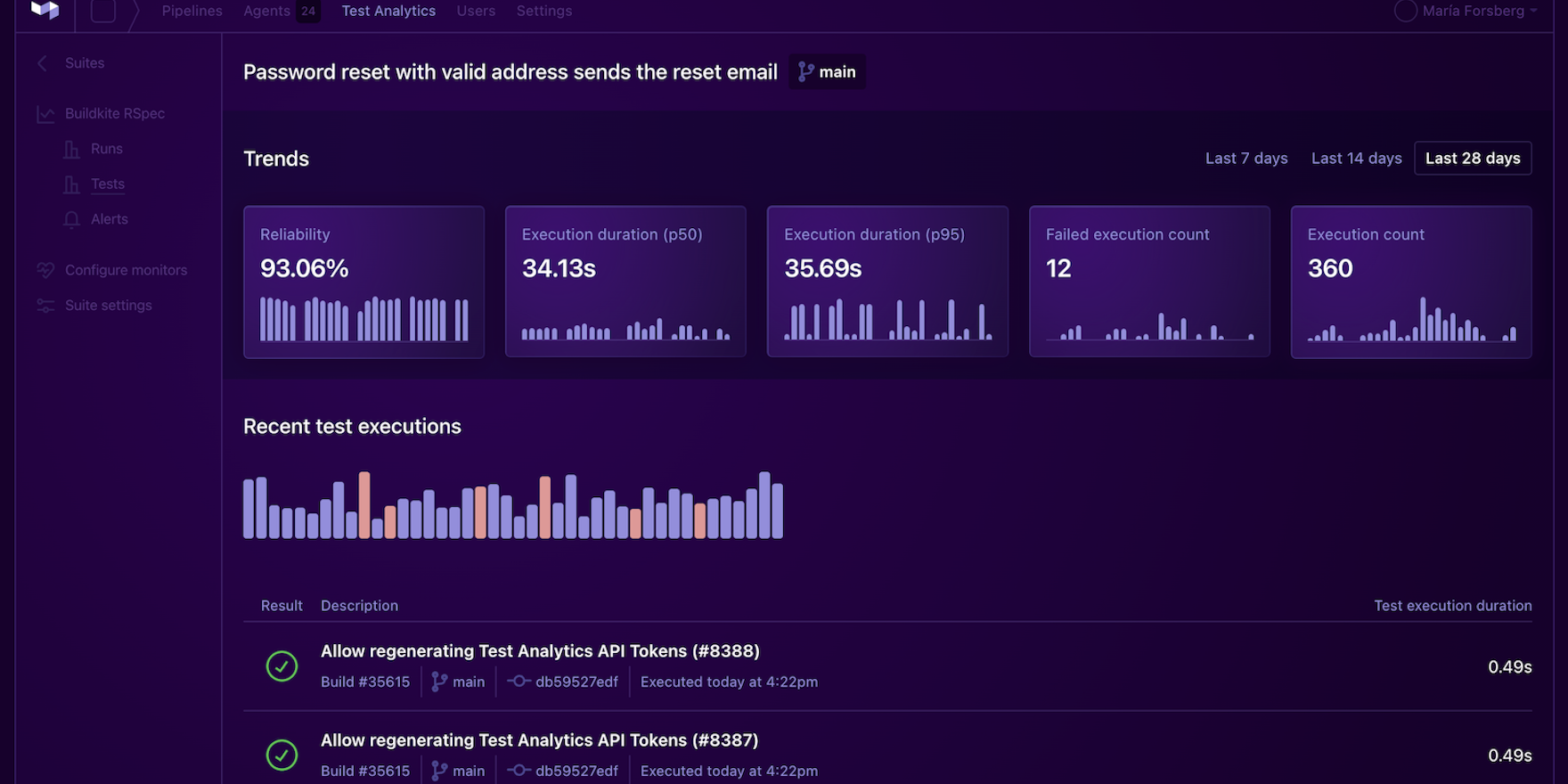
Buildkite’s newly released Test Analytics tool makes it easier to identify, track, and fix/replace problematic flaky tests. It integrates with your test runner and can work with any CI/CD platform to give you in-depth information about your tests in real-time.