At Buildkite, we've historically stored our data with two keys. We use sequential primary keys for efficient indexing, and UUID secondary keys for external use. The upcoming UUIDv7 standard offers the best of both worlds; its time-ordered UUID primary keys can be utilized for indexing and external use. This blog post will take you on the journey Buildkite took that led to our eventual adoption of UUIDv7 as the primary key of choice. We’ll explore the tradeoffs of database indexes; from sequential integers, randomly generated UUIDs, through to time-based identifiers.
What are UUIDs?
UUIDs (Universally Unique Identifiers) are unique identifiers that can be generated independently without a central authority or coordination with other parties. With large modern applications and systems being distributed in nature, UUID-shaped identifiers have gained popularity as database keys. Unlike sequential integer identifiers, which need coordination to guarantee global uniqueness in a distributed database, UUIDs eliminate the burden of coordination, making them preferable in sharded database environments.
UUIDs also provide other advantages in comparison to sequential integer identifiers. The unpredictability of UUID allows their public usage without disclosing sensitive internal information and statistics. UUIDs are also difficult to guess, providing an extra layer of defense alongside access control checks to guard against Insecure Direct Object Reference vulnerabilities.
The random nature, and large 128-bit size of UUIDs makes the probability of a duplicate UUID close to zero, meaning we can consider UUIDs as practically unique. However, the random nature of standard non-time-ordered UUIDs (such as v4) can create database performance problems when used as primary keys. This problem is often referred to as poor database index locality.
Using dual identifiers
A couple of years ago we decided to standardize the use of sequential integer IDs as primary keys, due to the significant performance issues of non-time-ordered UUIDs. We also use UUIDs as secondary identifiers on database tables. Queries involving table joins utilize sequential integer foreign keys––which typically perform better than random UUID foreign keys. For anything external and customer-facing, UUIDs are used (for example in the API and in URLs). This dual identifier approach was standardized across all teams to help engineers be more productive.
Understanding poor index locality
Non-time-ordered UUIDs values generated in succession are not sequential. The randomly generated values will not be clustered to each other in a database index, and thus inserts will be performed at random locations. This random insertion can negatively affect the performance on common index data structures such as B-tree and its variants.
The nature of Buildkite's products mean recent data is accessed more frequently than old data. With non-sequential identifiers, the most recent data will be randomly dispersed within an index and lack clustering. As a result, retrieving the most recent data from a large dataset will require traversing a large number of database index pages, leading to a poor cache hit ratio (how many requests a cache is able to fill successfully, compared to how many requests it receives). Compare this to the use of sequential identifiers, where the latest data is logically arranged on the right-most part of an index, allowing it to be far more cache-friendly.
Improving how UUIDs work
The index locality problem has led to many implementations in the past 10+ years. A common solution is to use a time-based unique identifier. The first component (prefix) of the identifier is a sortable timestamp which allows these identifiers to be inserted in sequential (and clustered) order into an index data structure. Because the generated identifiers are sequential, the insert performance is comparable to an insert of sequential integer identifiers.
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| time stamp | | random |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+Depending on the implementation, the remaining component of the identifier may be completely randomly generated, or machine-sequential and encoded with a machine/shard number. Examples of the described implementation include ULID, Instagram's ShardingID, Twitter X's Snowflake and Mastodon's modified version of Snowflake.
Experimenting with time-ordered UUIDv4
In 2022, a new proposed standard for time-ordered UUIDs started to gain traction, with the UUIDv7 specification becoming an RFC internet draft.
Around this time Buildkite started experimenting with time-ordered UUIDv4-compatible UUIDs.
- The first 48 bits (previously random) became a timestamp.
- The version bits remained unchanged, allowing the time-ordered UUIDs to be treated as if they were regular UUIDv4 values.
- Maintaining v4 compatibility was important for some Buildkite customers. During this experiment, Buildkite tried to set the version to '7' and discovered this broke some downstream customer systems which validated UUIDs but didn't know about UUIDv7 yet.
With this change (along with several other changes over a 6 week period), we observed a 50% reduction in the WAL (Write Ahead Log) rate of the primary database. A similar reduction in write IO was also observed. This reduction in the WAL rate allowed the team to easily set up read replicas and perform other database migration tasks.
Introducing UUID Version 7
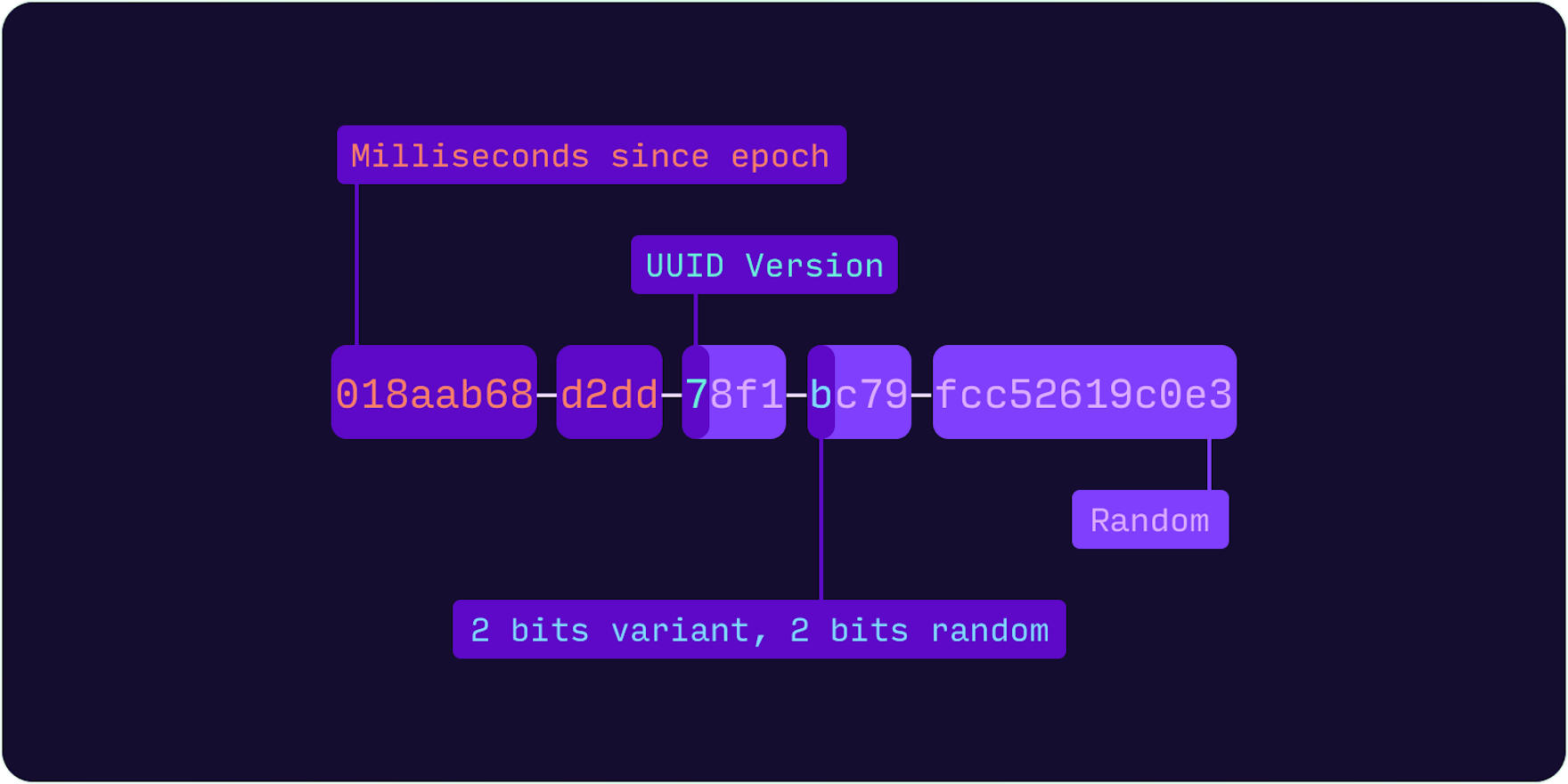
UUID Version 7 (UUIDv7) is a time-ordered UUID which encodes a Unix timestamp with millisecond precision in the most significant 48 bits. As with all UUID formats, 6 bits are used to indicate the UUID version and variant. The remaining 74 bits are randomly generated. As UUIDv7 is time-ordered, values generated are practically sequential and therefore eliminates the index locality problem.
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| unix_ts_ms |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| unix_ts_ms | ver | rand_a |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|var| rand_b |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| rand_b |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+The time-ordered nature of UUIDv7 results in much better DB performance compared to random-prefixed UUIDv4s. This post from the 2nd quadrant blog benchmarks random UUIDs against sequential UUIDs and not only shows improved write performance but also displays improved read performance.
UUIDv7 continues to conform with the standard UUID format so from a practical use perspective, they can be treated as if they were any other UUID. This compatibility characteristic allows us to use an existing Postgres UUID column and easily transition the column from storing UUIDv4 values to UUIDv7.
Migrating to UUIDv7 as the primary key
Earlier this year, we made the decision to use UUIDv7 as the primary key for all new tables (instead of sequential integer IDs).
Buildkite engineers are currently working on sharding our largest Postgres database. We quickly recognised using integer IDs as primary keys would quickly become a burden within a distributed database environment. The coordination and workarounds to ensure the uniqueness of incremental integer primary keys between databases is less than ideal. With the UUIDv7 standard being stable, and close to being finalized, Buildkite decided to begin using UUIDv7 as the primary key for all new tables.
Using UUIDv7 as the primary key will eliminate the need for coordinated identifier generation for new tables. We also no longer require a second integer identifier column, which simplifies application logic. These UUIDs can be used both externally in APIs, and also internally as foreign keys.
Alternatives considered and trade-offs
As a team, we considered numerous approaches, including Instagram's ShardingID implementation, and Shopify's composite primary key implementation. We contemplated retaining our bespoke time-ordered UUIDv4s. However, the novel and potentially complex nature of the approaches we investigated, along with the fact that UUIDv7 will likely become the future standard, led us to settle on UUIDv7 for Buildkite.
UUIDs are 128 bits long, twice as large compared to the 64 bit length of other alternative solutions. There is some additional storage overhead, but this is marginal when taking into account the storage of the rest of a database row, and the benefits of migration offset the overhead for our use case.
Looking ahead
Buildkite is currently on a journey to shard the Pipelines database by organization ID. Currently there is no need to encode database shard numbers into identifiers for our specific use case. However, it is worth noting that UUIDv8 (which roughly permits anything) could potentially be utilized in the future to incorporate shard numbers into identifiers if we find this necessary.
The new RFC for UUIDs is in its final review stages and I am looking forward to seeing UUIDv7 becoming an IETF Proposed Standard.